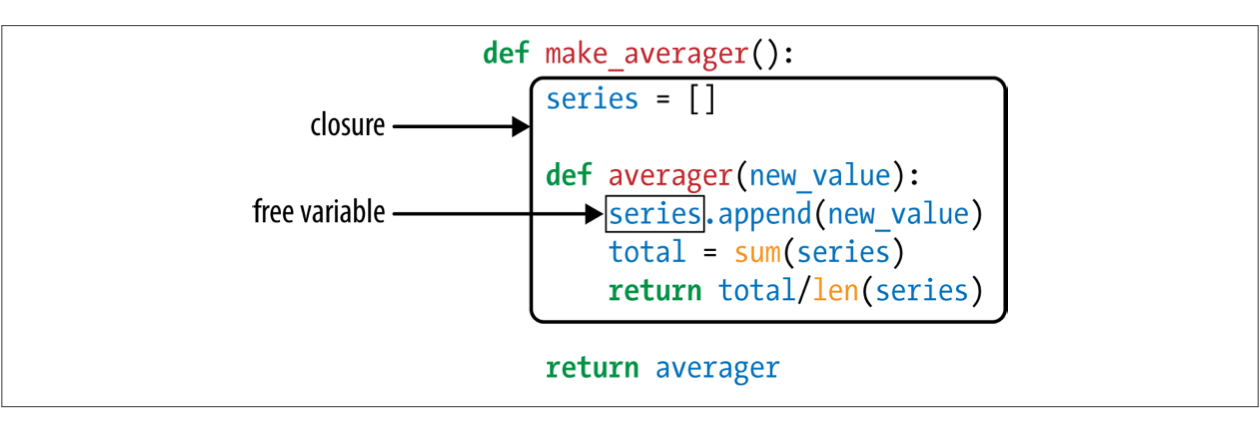
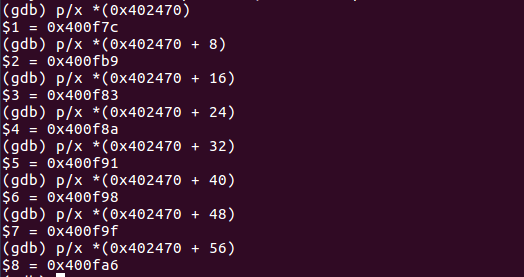
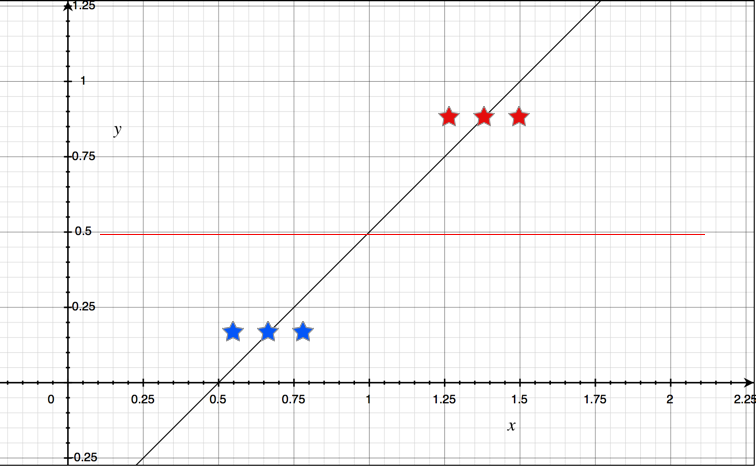
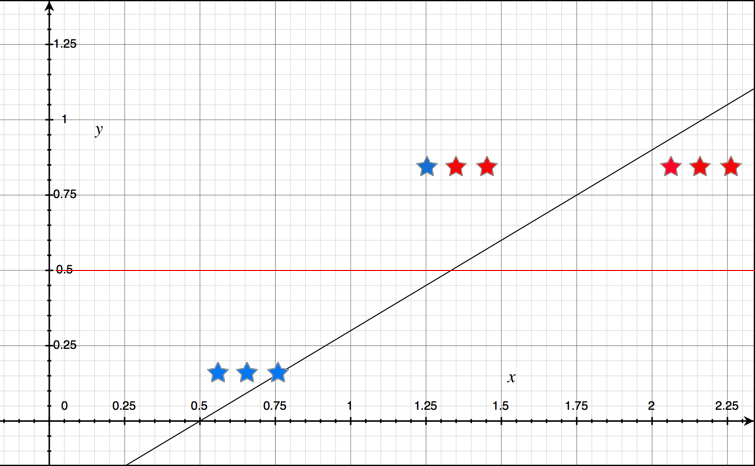
deffidelity_promo(order): """5% discount for customers with 1000 or more fidelity points""" return order.total() * .05if order.customer.fidelity >= 1000else0
defbulk_item_promo(order): """10% discount for each LineItem with 20 or more units""" discount = 0 for item in order.cart: if item.quantity >= 20: discount += item.total() * .1 return discount
deflarge_order_promo(order): """7% discount for orders with 10 or more distince items""" distinct_items = { item.product for item in order.cart } if len(distinct_items) >= 10: return order.total() * .07 return0
@promotion deffidelity(order): """5% discount for customers with 1000 or more fidelity points""" return order.total() * .05if order.customer.fidelity >= 1000else0
@promotion defbulk_item(order): """10% discount for each LineItem with 20 or more units""" discount = 0 for item in order.cart: if item.quantity >= 20: discount += item.total() * .1 return discount
@promotion deflarge_order(order): """7% discount for orders with 10 or more distince items""" distinct_items = { item.product for item in order.cart } if len(distinct_items) >= 10: return order.total() * .07 return0
defbest_promo(order): """Select best discount available""" return max(promo(order) for promo in promos)
>>> deff1(a): print(a) print(b) >>> f1(3) 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in f1 NameError: global name 'b'isnot defined
>>> b = 6 >>> deff2(a): print(a) print(b) b = 9 >>> f2(3) 3 Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in f2 UnboundLocalError: local variable 'b' referenced before assignment
注意到 3 被正确打印了,这说明 print(a) 被执行了。但是第二句 print(b) 没有运行。很多人有会很意外,认为 6 应该被打印,因为局部变量 b 在全局变量 b 被打印之后被赋值。
但事实上,当 Python 编译函数时,决定 b 是局部变量,因为它在函数内被赋值了。生成的二进制字节码也反映了这一点,b 会被从本地环境中获取。之后,当试图获取局部变量 b 的值得时候,会发现 b 未被绑定。
这并不是一个 bug,而是一个设计选择:Python 不要求用户声明变量,但是假设在函数内被赋值的变量是局部变量。这就比 JavaScript 强很多了,JavaScript 也不要求声明变量,但是如果你忘记了用 var 来声明局部变量,你可能会误用一个全局变量。
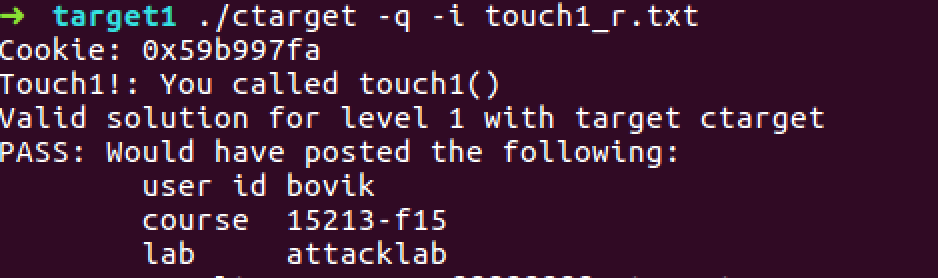
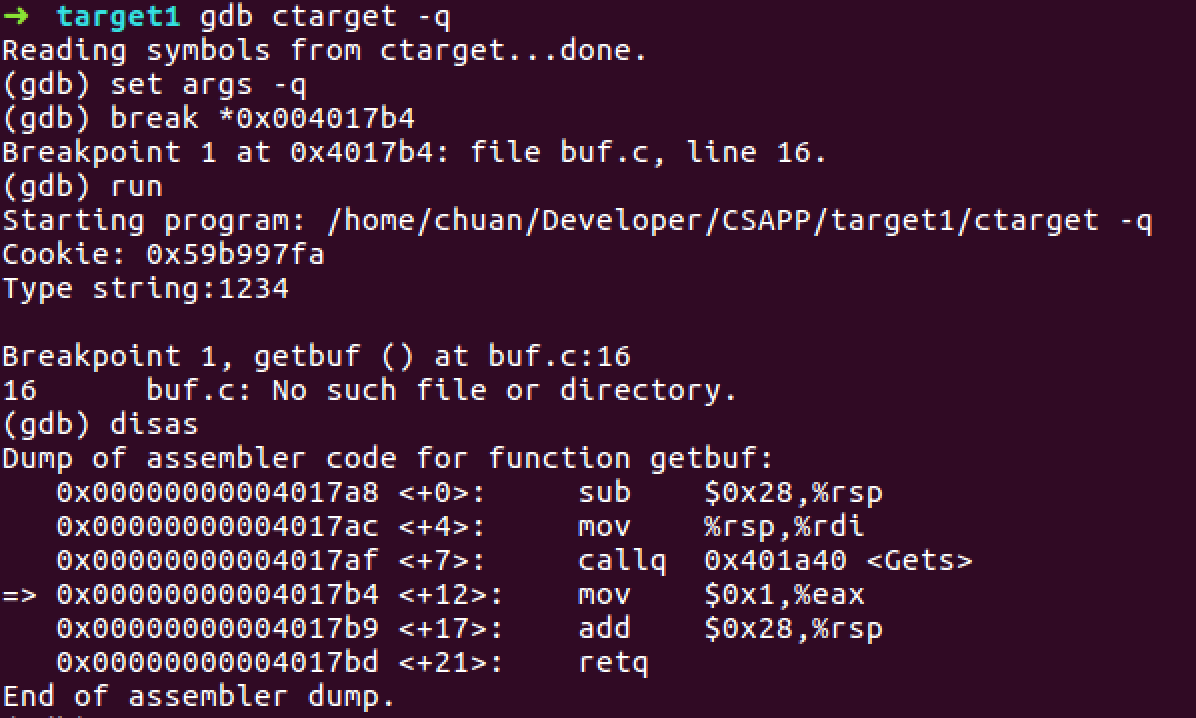
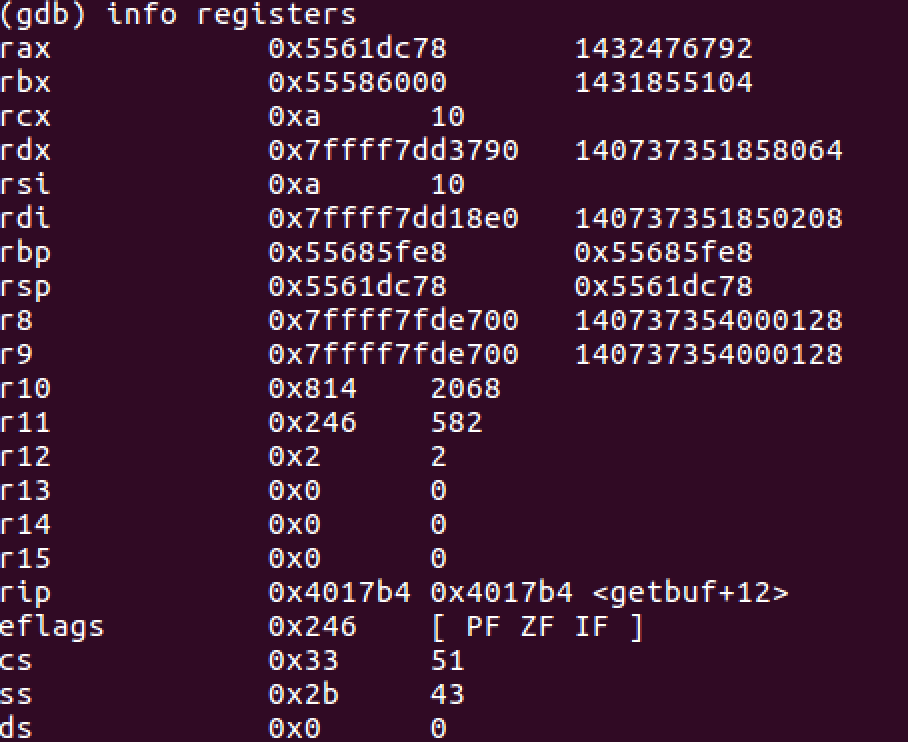
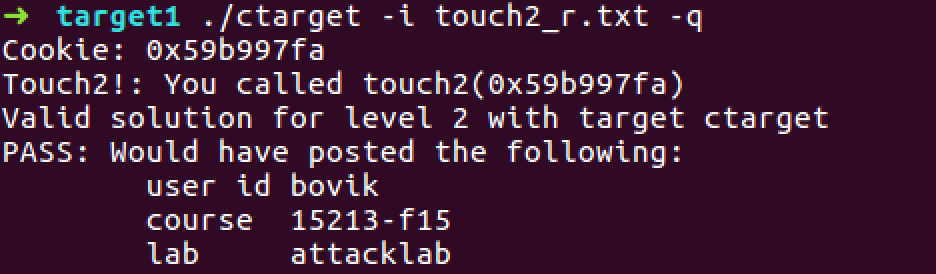
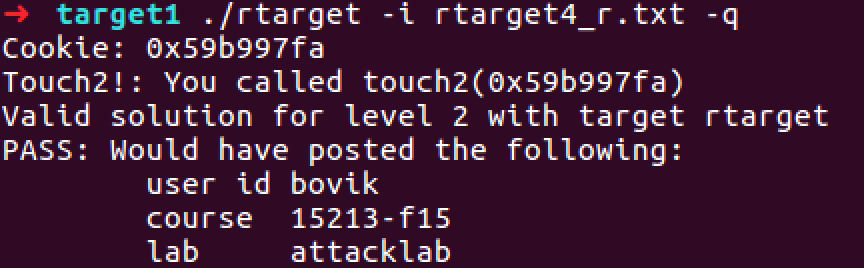
voidtouch2(unsigned val){ vlevel = 2; /* Part of validation protocol */ if (val == cookie) { printf("Touch2!: You called touch2(0x%.8x)\n", val); validate(2); } else { printf("Misfire: You called touch2(0x%.8x)\n", val); fail(2); } exit(0); }
/* compare string to hex represention of unsigned value */ inthexmatch(unsigned val, char *sval){ char cbuf[110]; /* make position of check string unpredictable */ char *s = cbuf + random() % 100; sprintf(s, "%.8x", val); returnstrncmp(sval, s, 9) == 0; }
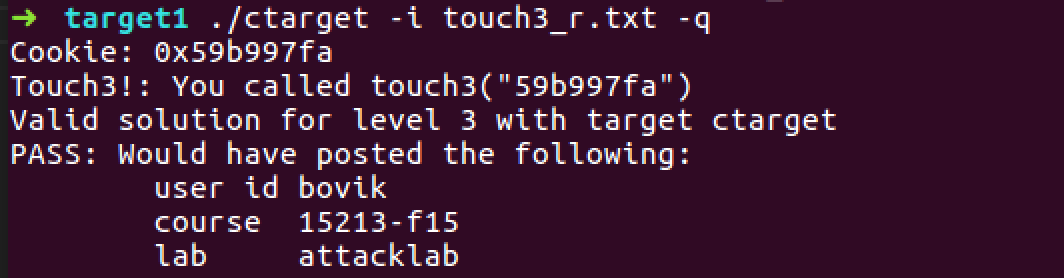
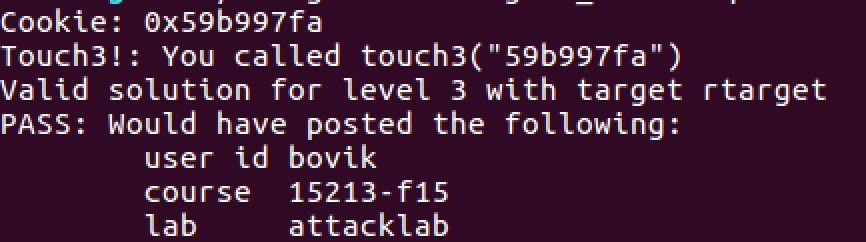
voidtouch3(char *sval){ vlevel = 3; if (hexmatch(cookie, sval)) { printf("Touch3!: You called You called touch3(\"%s\")\n", sval) validate(3); } else { printf("Misfire: You called touch3(\"%s\")\n", sval); fail(3); } exit(0); }
cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc ab 19 40 00 00 00 00 00 fa 97 b9 59 00 00 00 00 c5 19 40 00 00 00 00 00 ec 17 40 00 00 00 00 00
cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc cc ad 1a 40 00 00 00 00 00 d8 19 40 00 00 00 00 00 a2 19 40 00 00 00 00 00 fa 18 40 00 00 00 00 00 dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd dd 35 39 62 39 39 37 66 61 00
对象的 type 决定了对象支持哪些操作,以及该类型对象可能持有的值。type() 函数返回一个对象的类型,和 id 一样,一个对象的类型是不可改变的。
如果一个对象的 value 是可变的,那么这个对象就是可变的(mutable);如果对象的 value 是不可变的,那么这个对象也就是不可变的(immutable)。如果一个不可变的容器对象包含了可变对象的引用,那么虽然引用所指向的对象可以被改变,但是该容器仍然被认为是不可变的,因为它包含的引用并没有改变。一个对象的可变性(mutability)由该对象的 type 决定。比如,数字,字符串和 tuple 都是不可变对象,而字典和集合是可变对象。
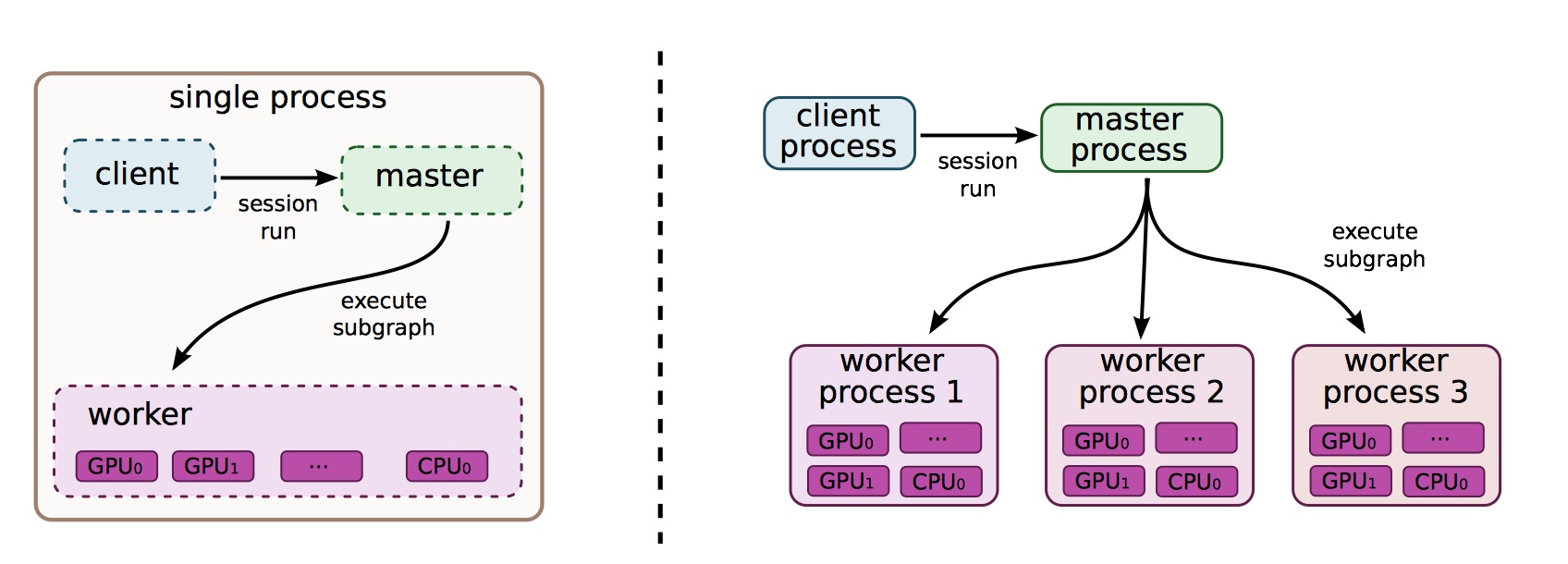
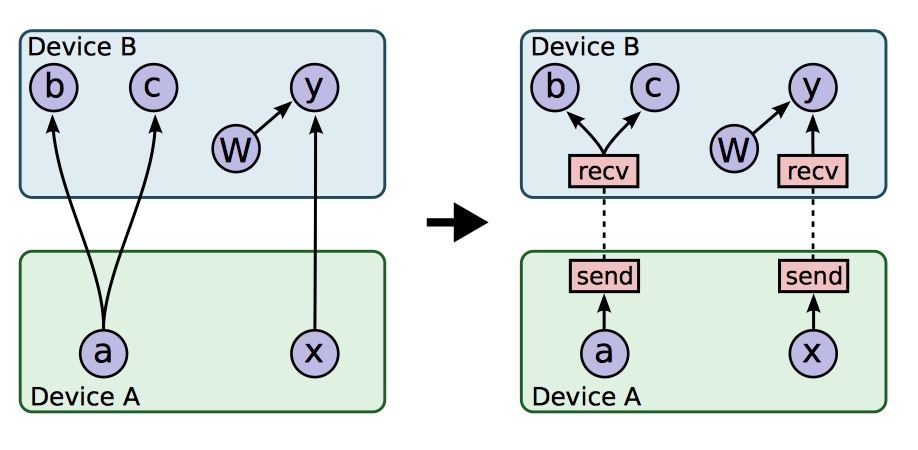
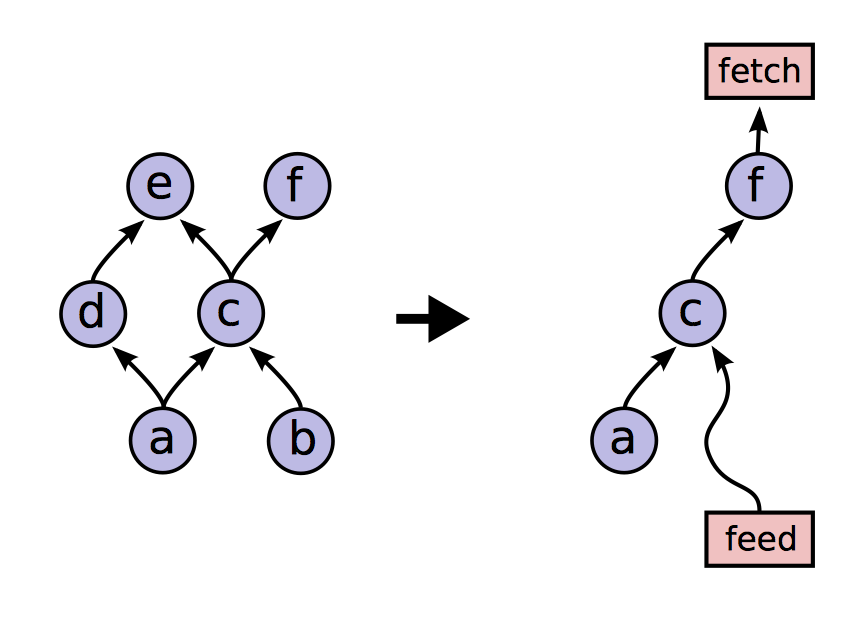
TensorFlow 支持部分子图的运行。当用户将整个数据流图构建完毕之后,可以调用 Run 方法来确定要运行的任意子图,并且可以向数据流图的任意边输入数据,或从任意边读取数据。数据流图中的每个节点都有一个名字,该节点的每个输出都由节点名和输出端口确定,如 bar:0 表示 bar 节点的第一个输出。Run 方法的两个参数就可以确定唯一的子图。
做完成这个题目的时候,我犯了一个错误。我认为整数在以 Intel 作为芯片的计算机使用小端存储,所以0x12345678在内存中的布局应该是0x78 0x56 0x34 0x12,那么如果要取得第 n 个字节的话,首先应该将x右移(3 - n) * 8位。按照我的错误理解,自然也得到了错误地结果。后来我在认识到:大/小端存储仅仅关系到整数的字节在内存的布局方式,当整数被加载在 CPU 中之后,字节的布局方式就不再存在大/小端的问题了
Endianness only matters for layout of data in memory. As soon as data is loaded by the processor to be operated on, endianness is completely irrelevent. Shifts, bitwise operations, and so on perform as you would expect (data logically laid out as low-order bit to high) regardless of endianness
这个题目要注意的一点就是在 C 语言中||、&&和!是逻辑运算,而~、&、|和^是位级运算。在逻辑运算中,任何非零参数都是表示 True,0 表示 False。所以bang(3)=bang(-3)=0,而bang(0)=1。我们知道在整数的补码表示中+0和-0的符号为都为 0。根据这个特点,可以得到解法:
1 2 3 4 5 6 7
intbang(int x){ int negx = ~x + 1; int x_sign = (x >> 31) & 0x1; int negx_sign = (negx >> 31) & 0x1;
return (x_sign | negx_sign) ^ 0x1; }
tmin
要求:返回使用2进制补码表示的最小的整数
允许操作:! ~ & ^ | + << >>
操作数限制:4
了解补码的表示方式后,直接返回0x80000000即可。
1 2 3
inttmin(void){ return0x1 << 31; }
fitsBits
要求:如果x可以被 n 位的2进制补码表示则返回1,否则返回0
假定1 <= n <= 32
允许操作:! ~ & ^ | + << >>
操作数限制:15
n 位补码能够表示的数的范围是$[-2^{n-1}, 2^{n-1}-1]$,所以如果在这个范围内则返回1,否则返回0。如果x大于$2^{n-1}-1$,则会发生正溢出,得到负数;如果x小于$-2^{n-1}$则会发生负溢出。所以题目的求解方法就是将x的符号位从第 n 位拓展到第32位得到extened_x,之后通过判断x == exntened_x来判断是否发生了溢出。