非线性假设(Non-Linear Hypotheses)
使用非线性的多项式可以帮助我们建立更好的分类模型。加入我们使用100个特征来构建一个非线性多项式模型,即使我们仅仅采用两两组合的方法,那么结果也将有超过5000个组合而成的模型,这对于一般的逻辑回归来说需要计算的特征太多了。
正是因为普通的逻辑回归不能很好地处理这么多特征,所以我们需要使用神经网络。
概念
神经网络是由具有适应性的简单单元组成的广泛并行互联的网络,它的组织能够模拟生物神经系统对真实世界物体所作出的交互反应。
神经网络的表示
神经网络中最基本的处理单元被称为神经元(Neuron),它包含多个输入,和一个输出。我们也可以将每个神经元当做一个学习单元,每个单元均采纳多个特征作为输入,并根据本身的模型得到一个输出。将多个神经元按照一定层次组合起来,就得到了神经网络(Neural Network)。一个以逻辑回归模型作为自身学习模型的神经元可以用下图表示,其中的参数可称为“权重(Weight)”。
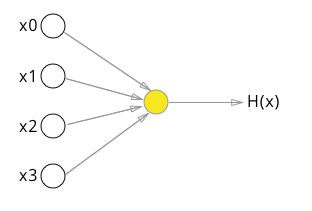
$$ h_\theta(x)=\frac{1}{1+e^{-\theta^{T}x}} $$
神经网络是许多逻辑单元按照不同层次组织起来的网络,每一层的输出变量是下一层的输出变量。以三层神经网络为例,第一层为输入层(Input Layer),中间一层为隐藏层(Hidden Layers),最后一层为输出层(Output Layer)。
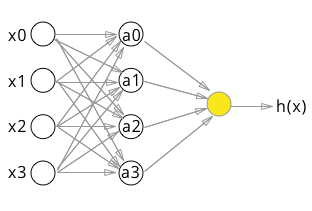
对于上图的模型,激活单元和输出分别表达为:
$$a_1=g(\theta_{10}x_0 +\theta_{11}x_1+\theta_{12}x_2+\theta_{13}x_3)$$
$$a_2=g(\theta_{20}x_0 +\theta_{21}x_1+\theta_{22}x_2+\theta_{23}x_3)$$
$$a_3=g(\theta_{30}x_0 +\theta_{31}x_1+\theta_{32}x_2+\theta_{33}x_3)$$
$$h_{\theta}(x)=g(\theta_{10}^{(2)}a_0+\theta_{11}^{(2)}a_1+\theta_{12}^{(2)}a_2+\theta_{13}^{(2)}a_3)$$
正向传播(Forward Propagation)
我们可以使用向量化的方法来计算神经网络的值:
$$g\Bigg( \begin{bmatrix}
\theta_{10}^{(1)} & \theta_{11}^{(1)} & \theta_{12}^{(1)} & \theta_{13}^{(1)} \\
\theta_{20}^{(1)} & \theta_{21}^{(1)} & \theta_{22}^{(1)} & \theta_{23}^{(1)} \
\theta_{30}^{(1)} & \theta_{31}^{(1)} & \theta_{32}^{(1)} & \theta_{33}^{(1)}
\end{bmatrix} \times \begin{bmatrix}
x_0 \\ x_1 \\ x_2 \\ x_3
\end{bmatrix}\Bigg) = g\Bigg( \begin{bmatrix}
\theta_{10}^{(1)}x_0 + \theta_{11}^{(1)}x_1 + \theta_{12}^{(1)}x_2 + \theta_{13}^{(1)}x_3 \
\theta_{20}^{(1)}x_0 + \theta_{21}^{(1)}x_1 + \theta_{22}^{(1)}x_2 + \theta_{23}^{(1)}x_3 \
\theta_{30}^{(1)}x_0 + \theta_{31}^{(1)}x_1 + \theta_{32}^{(1)}x_2 + \theta_{33}^{(1)}x_3
\end{bmatrix}\Bigg) = \begin{bmatrix}
a_1^{(2)} \\ a_2^{(2)} \\ a_3^{(2)}
\end{bmatrix}$$
本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征$x_1, x2,\dots,x_n$,我们虽然可以使用一些二项式组合来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的特征。
感知机与多层网络
感知机(Perceptron)由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是M-P神经元,亦称“阈值逻辑单元”。我们可以使用感知机来实现与、或、非运算。
- “与”($x_1 \wedge x_2$):令$\theta_0=-30, \theta_1=20, \theta_1=20$
- “或”($x_1 \vee x_2$):令$\theta_0=-10, \theta_1=20, \theta_1=20$
- “非”($\neg x_1$):令$\theta_0=10, \theta_1=-20$
我们也可以利用组合神经元来组合成为更为复杂的神经网络以实现更复杂的运算,我们也可以使用多层神经网络来实现多分类任务。
参数学习
代价函数
在逻辑回归中,我们的代价函数定义为:
$$J(\theta)=-[\frac{1}{m}\sum_{i=1}^{m}(y^{(i)} \times log(h_{\theta}(x^{(i)}))+(1-y^{(i)}) \times log(1-h_{\theta}(x^{(i)})))]+\frac{\lambda}{2m}\sum_{j=1}^{m}\theta_{j}^{2}$$
在逻辑回归中,我们只有一个输出变量,又称标量(scalar),也只有一个因变量y,但是在神经网络中,我们可以有很多输出变量,我们的$h_\theta(x)$是一个维度为K的向量,而且我们训练集中的因变量也是同样维度的一个向量,因此我们的代价函数会比逻辑回归更加复杂一些,为:
$$J(\theta)=-\frac{1}{m}\Big[\sum_{i=1}^{m}\sum_{k=1}^{K}y_k^{(i)}log(h_{\theta}(x^{(i)}))_k + (1-y_k^{(i)})log(1-(h_{\theta}(x^{(i)}))_k)\Big]+\frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_j+1}(\theta_{ji}^{(l)})^2$$
这个看起来复杂很多的代价函数背后的思想还是一样的,我们希望通过代价函数来观察算法预测的结果与真是情况的误差有多大,唯一不同的是,对于每一行特征,我们都会给出K个预测。我们可以对每一行特征都预测K个不同结果,然后再利用循环在K个预测中选择可能性最高的一个,将其与y中的实际数据进行比较。
反向传播算法(Back Propagation)
在正向传播算法中,我们从第一层开始正向一层层进行计算,知道最后一层的$h_\theta(x)$。
现在为了计算代价函数的偏导数$\frac{\partial}{\partial\theta_{ij}^{(i)}}J(\theta)$,我们需要采用反向传播算法,就是首先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层。
我们以一个四层的神经网络为例,最后一层的误差是激活单元的预测$a_{k}^{(4)}$与实际值$y_k$之间的误差。我们中$\delta$来表示:
$$\delta^{(4)}=a^{(4)}-y$$
我们利用这个误差值来计算前一层的误差:
$${\delta}^{(3)}=({\theta}^{(3)})^{T}{\delta}^{(4)}.*g’(z^{(3)})$$
其中$g’(z^{(3)})$是S形函数的导数,
$g’(z^{(3)})=a^{(3)}.*(1-a^{(3)})$。而$(\theta^{(3)})^{T}\delta^{(4)}$
则是权重导致的误差的和。下一步继续计算第二层的误差:
$$\delta^{(2)}=(\theta^{(2)})^{T}\delta^{(3)}.*g’(z^{(2)})$$
因为第一层是输入变量,不存在误差。我们有了所有的误差的表达式后,便可以计算代价函数的偏导数。假设我们不做任何归一化处理:
$$\frac{\partial}{\partial\theta_{ij}^{(l)}}J(\theta)=a_{j}^{l}\delta_{i}^{l+1}$$
反向传播算法的过程可以表述为:
有训练集${(x^{(1)}, y^{(1)}),\dots,(x^{(m)}, y^{(m)})}$
- 对于所有的$(l,i,j)$,设置$\delta_{ij}^{(l)}=0$
for traing_example t = 1 to m: - $a^{(l)}=x^{(t)}$
- 使用FP来计算$a^{(l)}$
- $\delta^{l} = a^{(l)} - y^{(t)}$
- $D_{i,j}=\frac{1}{m}(\delta_{ij}^{(l)}+\lambda\theta_{ij}^{(l)})$
梯度检验
当我们对一个较为复杂的模型(例如神经网络)使用梯度下降算法时,可能会存在一些不容易察觉的错误,意味着,虽然代价看上去在不断减小,但最终的结果可能不是最优解。
为了避免这样的问题,我们采用一种叫做梯度数值检验(Numerical Gradient Checking)方法。这种方法的思想是通过估计梯度值来检验我们计算的导数值是否真的是我们要求的。
对梯度的估计采用的方法是在代价函数上沿着切线的方向选择离两个点非常近的点然后计算两个点的平均值用以估计梯度。即对于某个特定的$\theta$,我们计算出在$\theta-\varepsilon$和$\theta+\varepsilon$的代价值,然后求两个代价的平均,用以估计在$\theta$处的代价值。
随机初始化
任何优化算法都需要一些初始的参数。到目前为止我们都是初始所有参数为0,这样的初始方法对于逻辑回归来说是可行的,但是对神经网络来说是不可行的。如果我们令所有的初始参数都为零,这意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为一个非0的数,结果也是一样的。
所以,我们通常初始参数为正负$\varepsilon$之间的随机值。
总结
我们在使用神经网络时,第一件要做的事情就是要选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
- 第一层的单元数既是我们训练集的特征数量
- 最后一层的单元数是我们训练集的结果的类的数量
- 如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好
训练神经网络的步骤为:
- 参数的随机初始化
- 利用正向传播方法计算所有的$h_{\theta}(x)$
- 编写计算代价函数$J$的代码
- 利用反向传播方法计算所有偏导数
- 利用数值检验方法检验这些偏导数
- 利用优化算法来最小化代价函数
深度学习(Deep Learning)
一般来说,参数越多的模型复杂度越高、“容量”越大,能完成更复杂的学习任务。很深层的神经网络学习模型被称为深度学习模型。对神经网络模型,提高容量的方法就是增加隐藏层的数目。隐藏层多了,相应的神经元连接权、阈值等参数也就越多。然而,多隐层神经网络难以直接用BP算法进行训练,因为误差在多隐层内逆传播时,往往会“发散”而不能收敛到稳定状态。
无监督逐层训练(Unsupervised Layer-wise Training)是多隐层网络训练的有效手段,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,这称为“预训练”;在训练完成之后,再对整个网络进行“微调”训练。
“预训练+微调”的做法可视为将大量参数分组,对每组先找到局部看起来比较好的设置,然后在基于这些局部较优的结果联合起来进行全局寻优。这样就在利用了模型大量参数所提供的自由度的同时,有效节省了训练开销。
另一种节省开销的策略是“权值共享”(weight sharing),即让一组神经元使用相同的连接权。这个策略在卷积神经网络(Convolutional Neural Network)中发挥了重要作用。
总的来说,深度学习是通过多层处理,逐渐将初始的“底层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此,我们可以将深度学习理解为进行“特征学习”或表示学习。
参考文献
- 机器学习 周志华
- Machine Learning Stanford