最近学习机器学习用到了 TensorFlow,所以找来了 Google Brain 团队发表的关于 TensorFlow 的论文学习,以下是一点笔记。
TensorFlow 的起源
Google 在成立 Google Brain 之后,为了内部研究和开发机器学习和深度神经网络的需要,开发了「DistBelief」,并且去得了很好得成果。在 「DistBelief」的基础上,Google Brain 团队对所期望的系统有了更深入的理解,在加上新的对机器学习系统在不同运算环境中运行的需求,Google Brain 开发了 TensorFlow。
编程模型和基本概念
一个 TensorFlow 的计算过程被描述为一个有向图(directed graph),这个有向图由许多node 组合而成。不同的 node 可能保存着持久化的状态,也可能用来实现分支或循环操作。
在一个 TensorFlow 的数据流图中,每个 node 有零个或多个输入,也有零个或多个输出,并代表某个操作(operation)的实例化过程。在数据流图中普通边上流动的值被称为 *tensor,代表任意维度的数组。特殊的边被称为 control dependencies,这样的边上没有数据流动,只用来描述操作的依赖关系,用来后一个 *operation 必须在前一个 operation 完成之后才能执行。
下面是用 Python 实现的一个简单的数据流图:

实现的数据流图为:
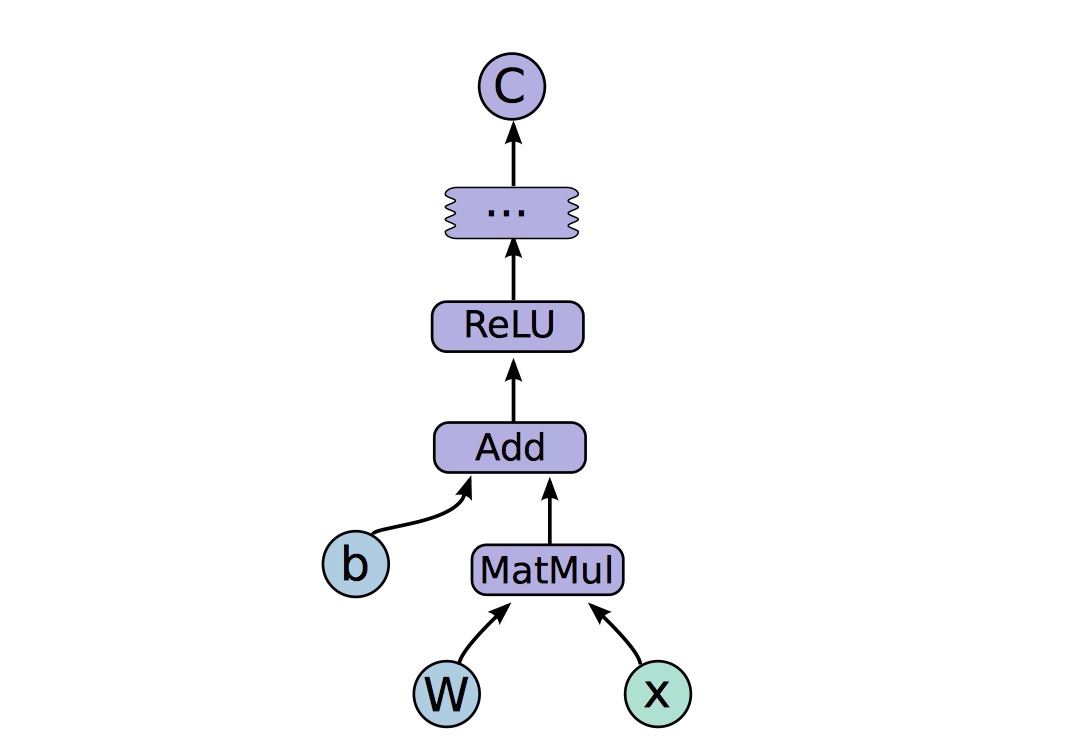
Operations and Kernels
一个 operation 拥有一个名字,并且对一个计算进行抽象(比如矩阵乘法和加法)。一个 operation 也有很多属性(attributes),所有的属性必须在数据流图被构建的时候被提供或被推断,从而使得 TensorFlow 可以实例化一个 node 来执行这个 operation。
一个 kernel 是对一种可以运行在专门硬件(如:CPU或 GPU)上的 operation 的实现。TensorFlow 使用一种注册机制来维护 operation 和 kernel 的集合,用户可以通过链接新的 operation 或 注册新的 kernel 在对 TensorFlow 进行拓展。
Session
用户通过创建一个 Session 来和 TensorFlow 交互。可以使用 Session 接口的 Extend 在对现有的数据流图进行拓展。Session 支持的另一个主要的操作是 Run*,它接受需要被计算的变量,和提供给数据流图的必要的数据来完成计算。调用 *Run 后,TensorFlow 会自动按照所定义的数据流图,并在遵守依赖关系的前提下完成计算。
Variables
通常,一个数据流图会被计算多次,大多数的 tensor 在数据流图的一次执行后就会消失。而一个 Variable 是一种特殊的 operation*,它可以返回一个指向在运算过程中持续存在的 *tensor 的引。这些引用可以被传递给其他操作来对 tensor 进行修改。在机器学习任务中,通常使用 Variable 来保存参数,并在数据流图的运算过程中不断更新。
实现
在一个 TensorFlow 系统中,用户通过 Session 和 TensorFlow 的 master 进程交互,master 进程将任务分配给不同的 worker 进程,而每个 worker 进程负责在一个或多个设备上执行运算。
TensorFlow 有「本地」和「分布式」的实现版本,其中「本地」的实现表示所有的运算都在同一个操作系统的进程中执行(该操作系统可能拥有多个 CPU 或 GPU);而「分布式」的实现支持有多台主机的多个进程共同完成计算任务。
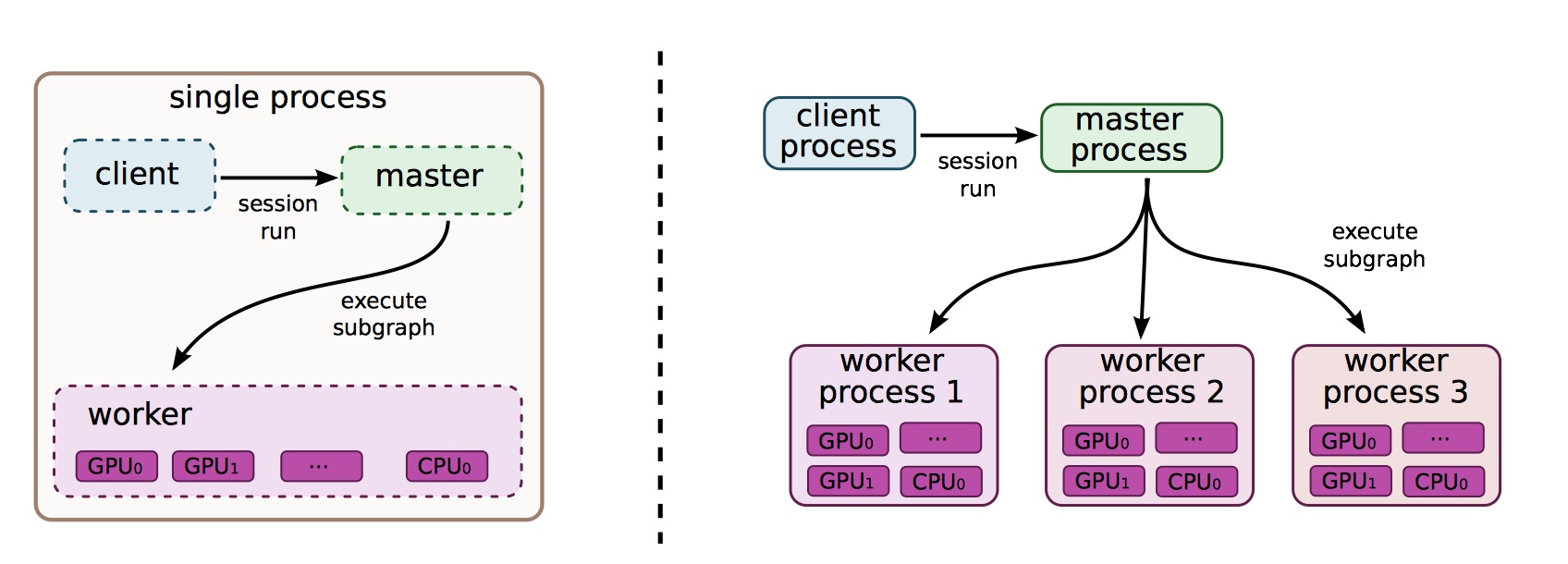
在 TensorFlow 中设备以及设备的名字和计算进程都会被合理的管理,用户可以通过注册的方法添加新的设备。
Tensor 在实现中是一个强类型的多维数组,Tensor 可以保存 从 8 bits 到 64 bits 的有/无符号整数、单/多精度的浮点数、复数和字符串类型。TensorFlow 使用引用计数来管理内存,当某个实例没有指向它的引用时,这个实例会自动被销毁。
TensorFlow 在单个设备上执行
TensorFlow 的最简单的执行模型是:一个 worker 进程在一个设备上进行计算。数据流图中 node 按照定义的相互依赖关系执行。TensorFlow 会保存每个 node 所依赖的,并且没有执行完毕的 node 的个数,当所有依赖的 node 执行完毕之后,该 node 会被加入一个「就绪队列」中,在这个队列中的 node 的执行顺序是不确定的。
TensorFlow 在多个设备上执行
对于拥有多个运算设备的系统,TensorFlow 需要解决两个难题:
- 决定在哪个设备上执行某个 node 的计算任务
- 管理设备间的数据交流
node 计算任务的分配
对于一个给定的数据流图,TensorFlow 会使用设备分配算法(placement algorithm)负责将计算任务映射到可用的设备上。设备分配分配算法需要将成本模型(cost model)作为参数,它包含了每个 node 中计算操作的输入和输入张量的大小(以字节为单位)和该 node 估计的计算时间。
设备分配算法模拟数据流图的计算过程并使用贪心策略(greedy heuristic)来为每个 node 分配运算设备。
设备分配算法首先从数据流图的源头开始对每个 node 的计算过程进行模拟。当某个 node 需要计算资源时,设备分配算法会将运行该计算的预计时间最短的可用设备分配给该节点。对于需要多个计算设备的 node,分配算法会使用贪心策略考虑将计算分配到不同设备后所需要的计算时间,并会考虑设备间数据通信的成本。总之,分配算法会将执行某计算操作最快的可用设备分配给 node。
设备间的通信
当设备分配算法结束时,数据流图会被划分为多个子图,每个子图对应一个计算设备。位于不同运算设备的任务 x 和 y 之间的通讯被新建的 Send 和 Receive node所接管。
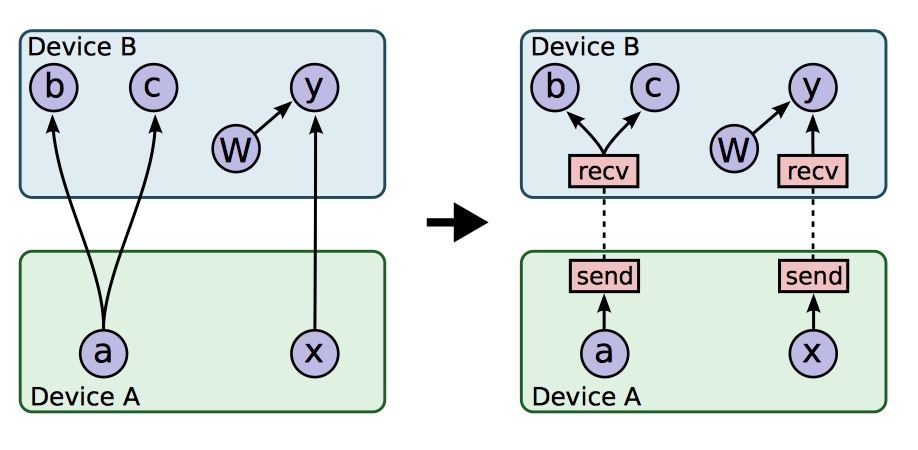
插入 Receive 和 Send 节点后,TensorFlow 使依赖于特定张量的操作使用同一个 Receive node,而不是每个操作都拥有一个 Receive node,这样可以避免不必要的内存分配,并可以解决数据同步问题。
这样处理设备通讯的方法可以使得管理分配在不同设备上的 node 实现去中心化。因为 Send 和 Receive nodes 解决了数据同步问题,所以 master 进程仅仅需要对每个 worker 进程发出运行指令,而不需要管理位于不同运算设备上计算任务之间的通信。
TensorFlow 在分布式系统上执行
TensorFlow 在分布式系统上的执行和在多个设备上的执行方式类似,在设备分配算法运行完后,每个子数据流图被分配到某个设备上,Send 和 Receive node 使用远程连接协议,比如:TCP 和 RDMA,在不同系统间传输数据。
容错
在分布式系统的运行过程中,错误可能在许多地方被检测到。TensorFlow 主要依赖于:
- 在 Send 和 Receive 之间的通信错误
- master 进程对每个 worker 进程的周期性检查
当某个错误被检测到时,整个数据流图的计算将被中断并且从头开始。注意,因为 Variable 保存在计算过程中持续存在的张量,所以 TensorFlow 将每个 Variable 与一个 Save 节点连接,Save 节点会定义保存 Variable 的状态。当错误发生时,TensorFlow 可以从 Save 保存的最近的状态恢复。
TensorFlow 的高级特性
梯度计算(Gradient Computation)
许多优化和机器学习算法,如随机梯度下降(stochastic gradient descent),需要计算损失函数对某些输入的梯度。TensorFlow 有内置的对自动计算梯度的支持。如果 TensorFlow 中的一个 tensor $C$ 依赖于集合 ${X_k}$ 中的 tensor,那么内置的函数可以自动返回 ${dC/dX_k}$ 。
当 TensorFlow 需要计算 tensor $C$ 对 tensor $I$ 的梯度时,它首先找到从 $I$ 到 $C$ 的计算路径,之后,从 $C$ 反向回溯到 $I$,对于反向路径上的每个节点,TensorFlow 都会添加一个节点,并根据前向操作使用求导的「链式法则」得到「梯度计算函数」。每个「梯度计算函数」可能被注册到任意操作,它会将偏导数和前向计算过程的输出作为输入。特别的,对于操作 $O$ 如果损失函数 $C$ 仅仅依赖于输出中的 $y_1$ 而不依赖于 $y_2$,那么 $d_C/d_{y_1}=0$。
添加梯度计算节点会影响 TensorFlow 的优化能力,尤其是对内存使用的优化。开发团队也正在努力优化 TensorFlow 的内存管理策略。
数据流图的部分执行(Partial Execution)
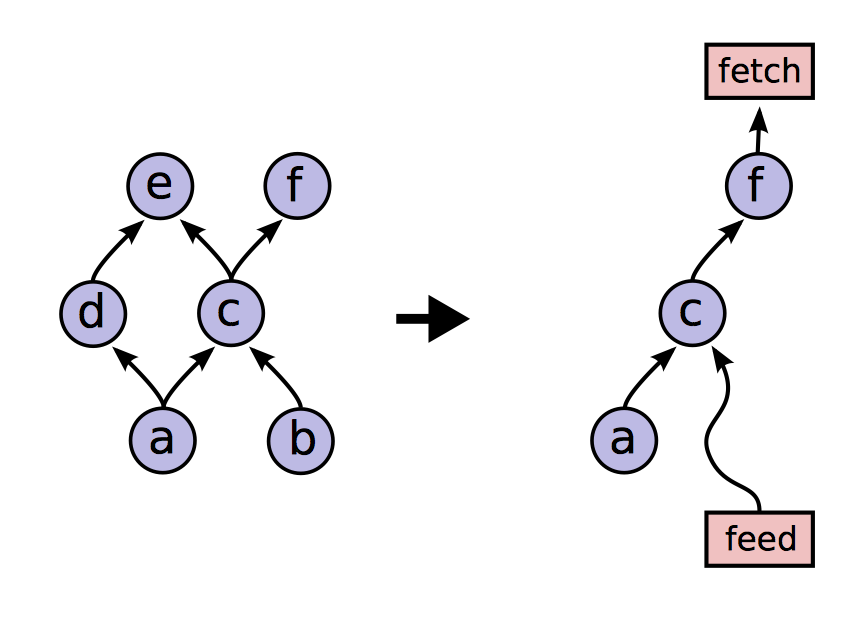
TensorFlow 支持部分子图的运行。当用户将整个数据流图构建完毕之后,可以调用 Run 方法来确定要运行的任意子图,并且可以向数据流图的任意边输入数据,或从任意边读取数据。数据流图中的每个节点都有一个名字,该节点的每个输出都由节点名和输出端口确定,如 bar:0 表示 bar 节点的第一个输出。Run 方法的两个参数就可以确定唯一的子图。
当计算一个子图时,会在为子图创建一个 feed 节点作为输入,fetch 节点用来接收输出。
设备限制(Device Constraints)
TensorFlow 的用户可以通过对 nodes 添加对计算设备的限制来控制 nodes 的运算设备分配。用户可以设置某 node 仅可以在 GPU 上运算,或仅可以在设备的某进程中计算。
控制流(Control Flow)
虽然没有任何明确控制流的数据流图的表达能力很强,但是支持了条件语句和循环可以产生更加简洁也更加高效的机器学习算法。
TensorFlow 中添加了一些基本的控制流操作,可以处理环状的数据流图。switch 和 merge 操作使我们可以跳过整个子图的执行;enter,leave 和 nextIteration 操作使我们可以表达迭代。更高阶的 if 和 while 语句可以使用这些基本的原语来实现。
TensorFlow 实现了 tags 和 frames 标记,循环中的每一次迭代都被赋予唯一的 tag*,循环的执行状态用 *frame 来分割。一个可用的输入可以再任意时候进入迭代,这样,多次可以被并行执行。
TensorFlow 使用分布式定位技术(Distributed Coordination Mechanism)来执行带有控制流的数据流图。一般来说,一个循环可能包含被分贝在多个运算设备的 node。所以,管理循环的状态就变成了一个分布式的终止探测问题。TensorFlow 通过使用图重写(graph rewriting)来解决这个问题。在数据流图分割过程中,TensorFlow 会在每个子图中添加控制节点。这些节点实现了一个状态机,可以检测每次迭代的开始和结束,并决定是否终止循环。
我们常常使用梯度下降来训练机器学习模型,并且将梯度的计算过程作为数据流图的一部分。当一个模型包含了控制流时,我们必须判断控制流分支的方向,再计算梯度;同样的,当一个模型拥有一个 while 循环时,我们需要依赖于循环的中间值来进行计算。TensorFlow 尝试重写子图来保存计算梯度所需要的信息。
输入操作(Input Operations)
TensorFlow 处理支持通过使用 feed node 来为计算提供数据外,也支持添加用于输入数据的 input node,它们使用文件名来配置,并可以每次执行时产生包含了一个或多个存储来文件中的数据的 tensor。
队列(Queues)
TensorFlow 中的队列允许数据流图中的不同部分异步地执行,并且通过 enqueue 和 dequeue 要求或提供数据。enqueue 可以将队列阻塞,直到有足够的可用空间,之后将数据放入队列;dequeue 将队列阻塞直到队列中有足够的可用元素。队列使得 TensorFlow 可以实现并行计算,当上一组数据仍在被用于计算时,下一组数据可直接被取出用于计算。
除了 FIFO 队列外,TensorFlow 还实现了 Shuffling Queue*,它可以随机地“打乱”队列中的元素,并输出其中一组。这样的队列对于需要 *shuffling 功能的机器学习算法十分关键。
容器(Container)
容器用于管理长期存在的可变状态。一个 Variable 被存储在一个容器内,默认的容器知道进程结束后才会被销毁。通过使用容器,可以实现在与多个不同 session 想关联的数据流图之间共享状态。
优化
TensorFlow 中做了许多重要的性能优化,主要有:
- Common Subexpression Elimination。TensorFlow 可以删除多余的计算操作,如同一个计算操作的多个具有相同输入输出的拷贝。
- Controlling Data Communication and Memory Usage。TensorFlow 通过规划计算操作的执行对系统的性能实现了优化,尤其是在数据转移和内存占用方面。
- Asynchronous Kernels。TensorFlow 拥有非阻塞的内核,该内核函数被传入一个计算任务,在之前的计算任务结束后,被传入的任务继续执行。
- Optimized Libraries for Kernel Implementations。TensorFlow 使用高度优化的数学运算库来实现操作。
- Lossy Compression。当在不同设备间传输数据时,TensorFlow 使用 lossy compression 来压缩高精度数据,从而加快传输效率。
TensorFlow 是 Google 在自己真实的人工智能经验上孵化出来的项目,非常值得我们学习。我觉得除了在学习工具外,对理论知识的学习才是重中之重,否则,即使进入了人工智能领域,码农也依然智能做搬砖的活儿。