什么是“控制器模型“
在 Kubernetes 中,Pod 是最小的 API 对象,是原子调度单位。Pod 通过对“容器”这个概念的进一步封装和抽象,添加更多属性和字段,使得描述及调度应用更加容易。而完成对 Pod 的调度和操作的逻辑就由控制器(Controller)实现。
控制器模型能够统一地实现对各种不同的对象或者资源的编排操作,保证对象和实际状态与对象的期望状态相同。对象的实际状态即直接访问 Kubernetes 的 ApiServer 得到的结果,而期望状态则来自于用户向集群提交的 Yaml 文件。以一个简单的部署了 Nginx 的 Deployment 控制器对象为例:
1 | apiVersion: apps/v1 |
这个 Deployment 确保携带了 app=nginx 标签的 Pod 个数永远等于 spec.replicas 指定的个数,即 2 个。那么,当集群中携带了 app=nginx 标签的 Pod 个数大于 2 的时候,控制器会删除多余的 Pod;反之,则会新建 Pod。
控制器模型的遵循 Kubernetes 中的一个通用编排模式:控制循环(control loop)。对于该 Deployment 我们可以用一段伪代码来描述这个控制循环:
1 | for { |
上述的伪代码中:
- Deployment 控制器从 Etcd 中查询所有携带了
app=nginx标签的 Pod,并计数得到实际状态; - 根据
spec.replicas得到期望状态; - Deployment 控制器根据比较两个状态的结果确定应该创建还是删除已有的 Pod。
像 Deployment 这种控制器的设计原理,实现了“一种对象控制另一种对象”。控制器对象本身负责定义被管理对象的期望状态,而被控制对象的定义则来自一个模板,即 PodTemplate。所以类似 Deployment 这样一个控制器,由上半部分包含了控制器定义及期望状态,加上下半部分被控制对象的模板组成。

Kubernetes 中通过使用控制器模型这个统一的编排框架,不同的控制器可以在具体的过程中设计不同的业务逻辑,达到不同的编排效果。
“控制器模型“与“事件驱动模型“的区别
笔者在接触 Kubernetes 之前,在业务中维持对象的状态一直采用的是“事件驱动模型”,即通过回调或者消息队列得到指令或事件后,执行一系列预先定义好的逻辑。这时,业务系统“被动”地等到具体事件的到来,并触发相应的操作。由于事件往往是一次性的,这导致在执行指令失败的情况下比较难以处理,通常是进行日志保存、报警及回滚操作。
而在 Kubernetes 中,控制器模型是持续、“主动”地观察目标对象的状态,不断尝试,最终实现实际状态与期望状态的一致。
声明式 API
在 Kubernetes 项目中,存在一个叫做 kube-controller-manager 的组件。这个组件,就是一系列控制器的集合。在 Kubernetes 项目的 pkg/controller 目录:
1 | ls -d */ |
这个目录的每个控制器都遵循通用的编排模式:控制循环(control loop),Deployment Controller 就是其中之一。
使用遵循“控制器模型”实现的各类 Controller,同 Kubernetes 里 API 对象的 CRUD 接口进行协作,完成用户业务逻辑的编写,也成为了 Kubernetes 的编程范式,实现了 Kubernetes 的声明式 API。
为了创建 Kubernetes 中的 API 对象,无一例外,用户都需要编写一个对应的 Yaml 文件交给 Kubernetes,这正是声明式 API 的一个要素。
但是声明式 API 并不仅仅意味着用 Yaml 文件代替命令行操作。例如,我们通过 kubectl create 命令创建 Deployment:
1 | kubectl create -f nginx.yaml |
通过 kubectl set image 命令更新容器镜像:
1 | kubectl set image deployment/nginx-deployment nginx=nginx:1.16.1 |
等等操作并不是声明式 API,这些应该被称为“命令式配置文件操作”。真正的声明式 API 是 kubectl apply 命令。用户可以使用 kubectl apply 创建 Deployment,之后修改 Yaml 并再次调用该命令将修改提交到 Kubernetes 的 ApiServer。kubectl create 及 kubectl replace 的执行过程,是使用新的 Yaml 文件中的 API 对象去替换原有对象;而 kubectl apply 则是执行了一个对原有 API 对象的 PATCH 操作。
更进一步,kube-apiserver 在响应命令式请求(如,kubectl replace)时,一次只能处理一个写请求,否则可能产生冲突。而对于声明式请求(如,kubectl apply),一次能处理多个写操作,并且具备 Merge 能力。
所谓“声明式”,指的就是用户只需要提交一个定义好的 API 对象来“声明”期望的状态;“声明式” API 允许有多个 API 写端,以 PATCH 方式对 API 对象进行修改,而无需关心本地原始 Yaml 文件的内容;最后,Kubernetes 可以完成对实际状态和期望状态的调谐过程。
声明式 API 的设计
为了回答当一个 Yaml 文件被提交给 Kubernetes 后,它是如何创建出一个 API 对象的,我们需要知道在 Kubernetes 中,一个 API 对象在 Etcd 中的完整资源路径,是由 Group(API 组)、Version(API 版本) 和 Resource(API 资源类型)组成的。
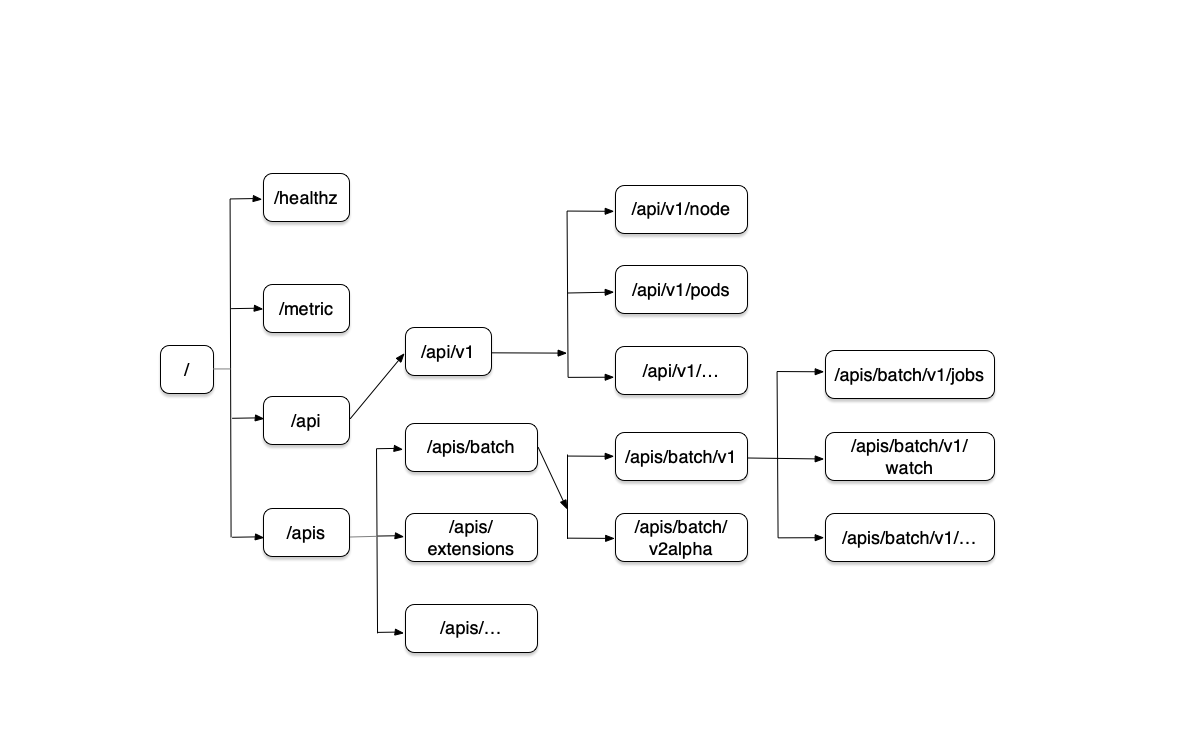
可以看到 Kubernetes 中的 API 对象的组织方式是层层递进的。以 Deployment 为例,那么 Yaml 的开始部分的写法为:
1 | apiVersion: apps/v1 |
在这个 Yaml 文件中,组(Group)为 apps,版本(Version)为 v1,资源类型(Resource)为 Deployment。当提交这个 Yaml 文件之后,Kubernetes 将会把这个 Yaml 文件里面描述的内容转换成集群内一个 Deployment 对象。
为了找到 API 对象的定义,首先 Kubernetes 会匹配 API 对象的组。对于核心 API 对象如 Pod、Node 等不需要 Group。所以对于核心对象,Kubernetes 会直接在 /api 这个层级下进行下一步匹配。而 Deployment 等非核心 API,Kubernetes 就需要在 /apps 下查找对应的 Group。
然后,Kubernetes 进一步匹配 API 对象的版本。对于 Deployment 对象来说,Kubernetes 在 /apps 这个 Group 下,匹配到的版本就是 v1。API 版本话管理保证了向后兼容。
最后 Kubernetes 匹配 API 对象的资源类型。最后,Kubernetes 就得到,要创建的对象是 /apps/v1/ 下的 Deployment 对象。
自定义资源类型(CustomResourceDefinition, CRD)
在 Kubernetes 中除了预定义的 API 对象外,用户可以利用 CRD 来向 kube-apiserver 中新增自定义 API 资源类型。例如,要在集群中添加一个描述网络资源的自定义 API 对象 Network,用以描述期望的网络参数。
这个 Network 对象的 Yaml 文件可以如下:
1 | apiVersion: sample.k8s.io/v1 |
那么,Kubernetes 应该如何知道该 API 对象 sample.k8s.io/v1/netword 的存在呢?其实,该 Yaml 文件是一个自定义 API 资源,也叫 Custom Resource(CR)。为了让 Kubernetes 知道这个 CR,就需要该 CR 的定义是什么,即CustomResourceDefinition(CRD)。
一个 CRD 的定义 Yaml 为:
1 |
|
文件中,指定了 “group: sample.k8s.io” 及 “version: v1”,也指定了这个 CR 的资源类型叫做 Network,复数是 networks。也声明了它的 scope 是 Namespaced,即这个 Network 是一个属于命名空间的对象。
通过执行:
1 | kubectl apply -f network.yaml |
即可在集群中创建 Network 对象的 CRD。
自定义控制器
“声明式 API” 并不像 “命令式 API” 那样有着明显的执行逻辑,这就使得集群声明式 API 的业务功能实现,通常需要控制器模式来监听 API 对象的变化,然后以此来决定实际需要执行的具体工作。
要实现一个自定义控制器,需要:
- 根据 kubeconfig 或者以 InClusterCofig 初始化用于访问集群 API 对象的
kubeClient,及用于访问自定义对象的自定义 Client,如networkClient; - 利用自定义对象的 Client 初始化对应的
InformorerFactory, 并使用它生成自定义对象的 Informer, 传给 controller; - 启动 informer 及 controller;
在 Kubernetes 中,一个自定义控制器的工作原理,可以用下图表示。

控制器的第一件事,是从 Kubernetes 的 APIServer 里获取关心的对象。这个操作,依赖 Informer 代码库完成。Informer 与 API 对象是一一对应的。
在创建 InformerFactory 的时候需要传递一个 client,实际上,Informer 正式利用这个 Client,与 APIServer 建立的连接。不过真正维护这个连接的,则是 Informer 所使用的 Reflector 包。
Reflector 使用被称为 ListAndWatch 的方法,来获取并监听目标对象的实例变化。
在 ListAndWatch 机制下,一旦 APIServer 端有新的对象实例被创建、删除或更新,Reflector 都会收到事件通知。这时,该事件及它对应的 API 对象这个组合,就被称为增量(Delta),它会被放入一个 Delta FIFO Queue 中。
另一方面,Informer 会不断从这个 Delta FIFO Queue 里读取(Pop)增量。每拿到一个增量,Informer 就会判断这个增量里的事件类型,然后创建或者更新本地对象的缓存。这个缓存,在 Kubernetes 中一般被叫做 Store。
例如,如果该事件类型是 Added,那么 Informer 就会通过一个叫做 Indexer 的库把这个增量里面的 API 对象保存在本地缓存中,并为它创建索引。相反,如果增量的事件是 Deleted,那么 Informer 就会从本地缓存中删除这个对象。
这个同步本地缓存的工作,是 Informer 的第一个职责,也是它最重要的职责。
Informer 的第二个职责,就是根据这些事件的类型,触发事先注册好的 ResourceEventHandler。这些 Handler 需要在创建控制器的时候注册给它对应的 Informer。
一个控制器的定义可以如下:
1 | func NewController( |
需要注意的是,在这个自定义控制器里面,还设置了一个工作队列(work queue),它正是图中间的 WorkQueue。这个工作队列的作用是,负责同步 Informer 和控制循环之间的数据。
然后,为 Informer 添加了三个 Handler,分别对应 API 对象的添加、更新和删除事件,而具体的处理操作则是将事件对应的 API 对象加入到工作队列中。实例入队列的不是 API 对象本身,而是它们的 key,及 {namespace}/{name}。
而控制循环,则是不断从工作队列里拿到 Key,然后开始执行真正的控制循环。
所以,Informer 其实就是一个带有本地缓存和索引机制的,可以注册 EventHandler 的 client。它是自定义控制器跟 APIServer 进行数据同步的重要组件。Informer 通过 ListAndWatch 方法,将 APIServer 中的 API 对象缓存在了本地,并负责更新和维护这个缓存。
ListAndWatch 首先通过 List API 获取所有最新版本的 API 对象;然后再通过 Watch API 实时更新本地缓存,并且调用这些事件对应的 EventHandler。
此外,每经过 resyncPeriod 指定的时间,Informer 维护的本地缓存,都会使用最近一次 List 返回的结果强制更新一次,从而保证缓存的有效性。这个强制更新的操作叫做 resync。
需要注意,这个定时 resync 的操作,也会触发 informer 的“更新”事件。但是此时,“更新”事件对应的 Network 实际上没有变化,这种情况下,Informer 不需要对这个更新事件再做进一步处理。
以上,就是 Informer 的工作原理了。
总结
控制器模型能够统一地实现对各种不同的对象或者资源的编排操作,保证对象和实际状态与对象的期望状态相同。对象的实际状态即直接访问 Kubernetes 的 ApiServer 得到的结果,而期望状态则来自于用户向集群提交的 Yaml 文件。
所谓“声明式”,指的就是用户只需要提交一个定义好的 API 对象来“声明”期望的状态;“声明式” API 允许有多个 API 写端,以 PATCH 方式对 API 对象进行修改,而无需关心本地原始 Yaml 文件的内容;最后,Kubernetes 可以完成对实际状态和期望状态的调谐过程。
Informer 是一个自带缓存和索引机制,可以触发 Handler 的客户端,缓存被称为 Store,索引被称为 Index。
Informer 使用 Reflector 报,通过 ListAndWatch 机制获取并监听 API 对象变化。
Informer 和 Reflector 之间使用一个增量先进先出队列来协同,而Informer 与控制循环之间则使用一个工作队列来协同。