为什么需要 Pod
Pod 是 Kubernetes 项目中最小的 API 对象;是 Kubernetes 项目的原子调度单位。但是,为什么需要 Pod 呢?
在学习容器本质后,我们都知道:
Namespace 做隔离,Cgroups 做限制,rootfs 作为文件系统。
Pod 存在的必要性是什么呢?
Pod 存在的主要目的为:1. 抽象进程组概念 2. 引入“容器设计模式”
Pod 对“进程组”概念进行了抽象。如果说容器的本质是云计算系统中的进程,那么 Kubernetes 就相当于云计算的操作系统。在一个真正的操作系统里,如果在终端输入 pstree 命令,就可以以树形结构展示系统中的进程。这时我们可以发现进程通常并不是独自运行,而是被有组织地组合在一起。如用于处理系统日志中的 rsyslogd,与内核日志模块 imklog 同属于一个进程组,他们协作完成日志的收集。Kubernetes 的很多设计思想来源与 Google 内部系统 Borg,在 Borg 的实践过程中,工程师就发现应用之间通常存在类似于“进程组”的关系,它们密切协作,必须部署在同一台机器上。如果存在了“组”的概念,那么就能很好地处理这样的运维关系,Kubernetes 按照 Pod 的资源需求进行计算进行资源调度。所以,Kubernetes 使用 Pod 将“进程组”的概念映射到了容器技术中,使其成为云计算“操作系统”里面的“一等公民”。
Pod 引入了“容器设计模式”。Pod 本身仅仅是一个逻辑概念。Kubernetes 仍然是使用 Namespace 和 Cgroups 实现资源的隔离和限制,而并不存在一个「Pod 边界」。Pod 里的所有容器,共享同一个 Network Namespace,并且能够声明共享同一个 Volume。如果共享网络配置及 Volume 是通过类似运行 docker run 命令来实现,如:
1 | docker run --net=other --volumes-from=other --name=this ... |
那么一个容器就必须比另外一个容器先启动,这样容器间就成为了拓扑关系,而不是对等关系了。所以,在 Kubernetes 中,Pod 使用了一个中间容器 Infra,Infra 一定是在 Pod 中首先被创建的容器,而其他容器则通过 Join Network Namespace 的方式与 Infra 容器关联在一起。
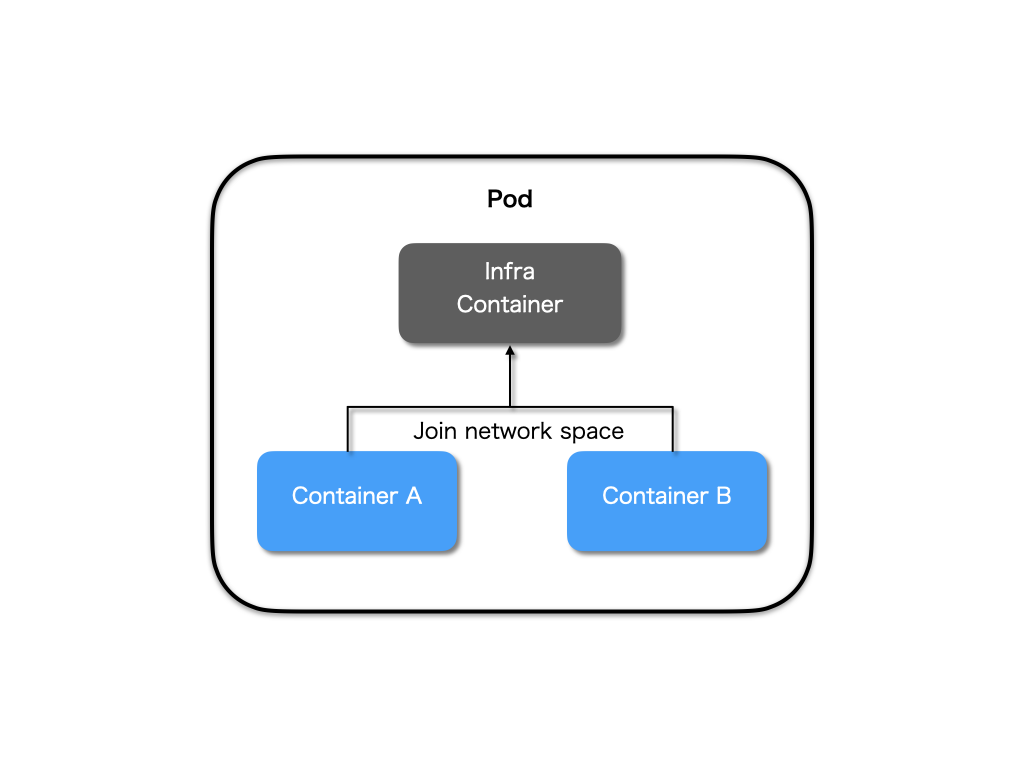
Infra 容器使用一个特殊的镜像,叫做:k8s.gcr.io/pause,它占用极少的资源。Infra 容器被创建后会初始化 Network Namespace,之后用户容器就可以加入到 Infra 容器中了。所以对于 Pod 中的容器 A 和 B 来说,它们:
- 能够直接使用 localhost 通信;
- 看到与 Infra 容器相同的网络设备
- Pod 只有一个 IP 地址,也就是该 Pod 的 Network Namespace 对应的 IP 地址;
- 所有网络资源均一个 Pod 一份,被 Pod 中所有容器共享;
- Pod 的生命周期仅与 Infra 容器一致,与用户容器无关。
对于同一个 Pod 中的用户来说,它们的进出流量可以认为都是通过 Infra 容器完成的。所以当进行网络插件开发时,应该主要考虑如何配置 Pod 的 Network Namespace,而不是去配置用户容器。
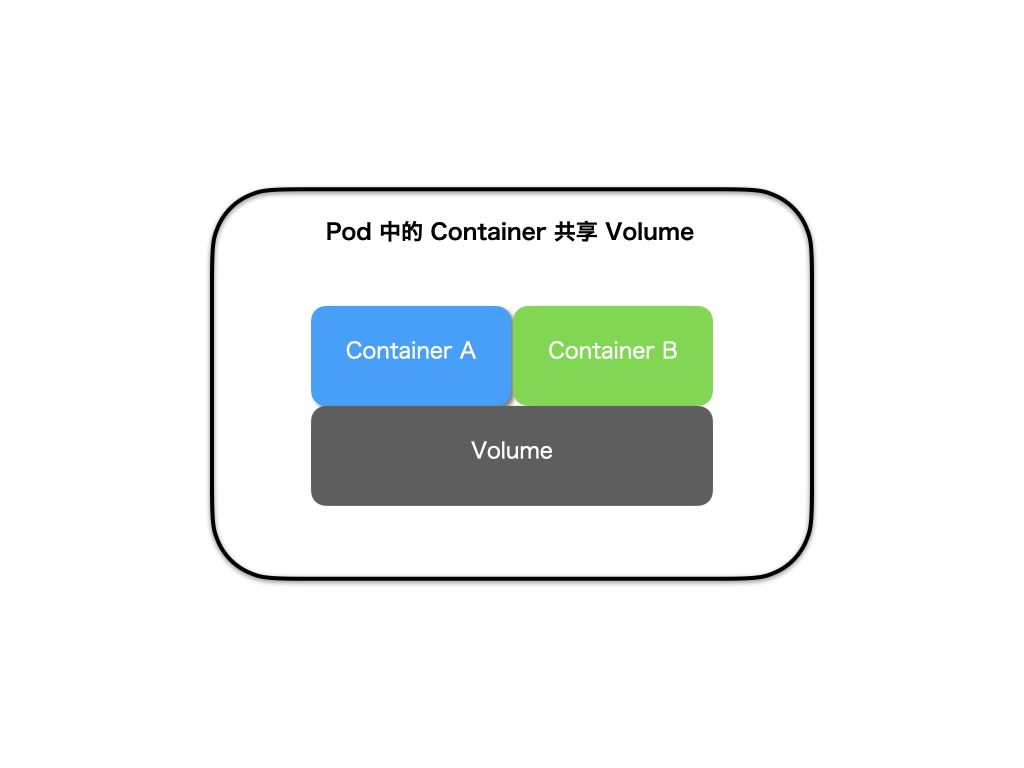
有了使用 Infra 容器的设置后,共享的 Volume 也就成为了 Pod 层级的字段。这样 Volume 对应的宿主机目录对于 Pod 来说只有一个,Pod 中的容器只要声明挂载这个 Volume,就一定可以共享这个 Volume 对应的宿主机目录。
Pod 的设计希望当用户想在一个容器里面运行多个功能不相关,但是关系紧密的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。
所以,当进行业务「上云」的时候,应该把整个虚拟机想象成一个 Pod,把这些进程分别做成容器镜像,把存在顺序关系的容器定义为 Init Container。这样就实现了更加合理的,容耦合的容器编排方法。
Pod 提供的是一种编排思想,而不是具体的技术方案。
Pod 对象的基本概念
Pod,而不是容器,是 Kubernetes 项目中的最小编排单位。如果将这个思想落实到 API 和数据接口定义上,那么容器就成为了 Pod 属性中一个普通的字段。那么,哪些属性应该放到 Pod 中,哪些应该放到 Container 中呢?
Pod 扮演了传统环境中的「虚拟机」角色,容器扮演了进程。理解了 Pod 的设计原则之后,我们就可以明白,在设计 Pod 数据结构时:
- 凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的;
- 凡是跟容器的 Linux Namespace 相关的属性,一定是 Pod 级别的;
- 凡是 Pod 中容器要共享宿主机的 Namespace,一定是 Pod 级别的;
应用调度、网络、存储及安全相关的属性的共同特征是,它们描述“机器”这个整体,而不是里面的“程序”。
- NodeSelector:供用户将 Pod 与 Node 进行绑定。
1 | apiVersion: v1 |
这样的配置意味着 Pod 永远只能运行在携带了 disktype:ssd 标签(Label)的节点上;否则将会调度失败。
NodeName::该字段一般由调度器负责设置,因为一旦 Pod 中的该字段被赋值,Kubernetes 就认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。但是用户可以设置它来“骗过”调度器,一般在测试和调试时这样做。
NodeName:定义了 Pod 的 hosts 文件(/etc/hosts)中的内容。
1 | apiVersion: v1 |
当 Pod 启动后,生成的 /etc/hosts 文件的内容如下:
1 | cat /etc/hosts |
Linux Namespace 相关的属性,也一定是 Pod 级别的。因为 Pod 的设计原则就是希望其中的容器能够尽可能多地共享 Linux Namespace,仅保留必要的隔离和限制能力。这样 Pod 模拟出的效果会更加类似虚拟机中进程间的关系。
假如设置 sharePrecessNamespace=true:
1 | apiVersion: v1 |
就意味着 Pod 中的容器要共享 PID Namespace。之后,在 busybox 容器中运行 ps aux,就不仅仅能够看到 ps 命令本身,还能够看到 nginx 容器的进程以及 pause 进程。这就意味着,整个 Pod 里的每个容器的进程,对于所有容器来说都是可见的。
凡是 Pod 中的容器要共享宿主机的 Namespace,也一定是 Pod 级别的。比如:
1 |
|
这个 Pod 中我们定义了共享宿主机的 Network、IPC 和 PID Namespace。这就意味着,这个 Pod 里面的所有容器,会直接使用宿主机的网络、直接与宿主机进行 IPC 通信、看到宿主机里面正在运行的所有进程。
在 Pod 中,最重要的就是 Containers 了,另外,Init Container 也属于 Pod 对容器的定义,内容和 Container 完全相同,只是 Init Container 的声明周期会限于所有的 Containers,并且严格按照顺序执行。
Kubernetes 对 Container 的定义,与 Docker 相比差别不大,主要有:Image,Command,workingDir,Ports,及 volumeMounts。另外需要注意的有:
ImagePullPolicy:定义了镜像的拉取策略,默认值是
Always,即每次创建 Pod 时都重新拉取镜像;如果它的值被定义为Never或者IfNotPresent,则意味着 Pod 永远不会主动拉取这个镜像,或者只有当宿主机上不存在该镜像时才拉取。Lifecycle:定义了 Container Lifecycle Hooks,也就是容器状态发生变化时触发的一系列“钩子”。
1 | apiVersion: v1 |
可以看到在 Container 中为 nginx 容器设置了 postStart 和 preStop,分别表示在容器启动后或者在容器被杀死前执行一个指定的操作。
Pod 生命周期的变化,主要体现在 Pod 的 Status 部分,这是它除了 Metadata 和 Spec 之外的第三重要的字段。其中,pod.status.phase 就是 Pod 的当前状态,它可能的情况有:
- Pending。表示 Pod 的 YAML 文件已经提交给了 Kubernetes,对象已经被创建被保存在了 Etcd 中。但是 Pod 中的有些容器因为某种原因而不能被顺利创建。
- Running。表示 Pod 已经调度成功,其中包含的容器都已经创建成功,且至少有一个正在运行中。
- Succeeded。表示 Pod 中所有的容器都已经正常运行完毕,并且已经退出了。这在 Job 对象中较常见。
- Failed。表示 Pod 中至少有一个容器已不正常的状态(非 0 返回码)退出。
- Unknown。表示一个异常状态,Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,可能的原因是主从节点间的通信出现了问题。
更进一步。Pod 的 Status 字段还可以再细分中一组 Conditions。细分的状态包括:PodScheduled、Ready、Initialized,以及 Unschedulable。它们主要用于描述造成当前 Status 的具体原因是什么。
Pod 的实现原理
我们可以查看 Pod 数据结构的完整定义,来进一步理解 Pod 的设计。
1 | // Pod is a collection of containers that can run on a host. This resource is created |
与 Kubernetes 中任何一个 API 对象一样,Pod 首先也嵌入(embed)了 TypeMeta 和 ObjectMeta 属性。TypeMeta 中的 apiVersion 和 kind 描述了 API 组及资源类型,能够确定该对象应该由谁来处理。而 metadata 则为我们提供能够唯一识别对象的信息,包括集群中的 namespace 及在命名空间中唯一的 name,还有用于分类的 labels 字段及用于功能拓展的 annotations 字段。
1 | type ObjectMeta struct { |
其中最重要的属性为 PodSpec 的定义。它定义了 Pod 的期望状态,其中包含了大量本文中未介绍的属性。
Pod 的基本生命周期为,首先创建 Pod,之后进入健康检查状态,当 Kubernetes 确定 Pod 已经能够接受外部请求时,将流量打到新的 Pod 上并继续对外提供服务;如果 Pod 发生错误就触发重启机制。
Pod 的在集群中的创建由 kubelet 完成,Pod 的创建过程的入口为 SyncPod 方法。
创建 Pod 的流程基本可以分为 6 步:
- 计算 Pod 中沙盒和容器的变更;
- 强制停止 Pod 中对应的沙盒;
- 强制停止所有不应该运行的容器;
- 为 Pod 创建新的沙盒;
- 创建 PodSpec 中指定的初始化容器;
- 依次创建 PodSpec 中指定的常规容器;
1 | func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) { |
可以看出,Pod 的创建流程首先是计算 Pod规格和沙箱的变更,然后停止所有可能影响这一次创建或更新的容器,最后依次创建沙盒、初始化容器和常规容器。