绪论
我从这周开始在Course上开始了对Machine Learning的学习,注册了吴恩达教授的机器学习课程。所以我准备在自己的博客上整理课程的学习笔记,并记录自己的思考。
什么是机器学习
机器学习:致力于研究如何通过计算的手段,利用经验来来改善系统自身的性能。我们把经验数据提供给学习算法,它就能根据这些数据产生模型;在面对新的情况时,模型就可以给我们提供相应的判断。如果说计算机科学是研究关于“算法”的学问,那么我们可以说机器学习是研究“学习算法”的学问。
机器学习也有更学术化的定义:
假设用 P 来评估计算机程序在某任务上的性能,若一个程序通过利用经验 E 在 T 中任务上获得了性能呢改善,则我们就说关于 T 和 P,该程序对 E 进行了学习。 — Mitchell
注意,机器学习的目标是使学习得到的模型能很好得适用于新样本。
监督学习(Supervised Learning)和非监督学习(Unsupervised Learning)
根据训练数据是否有标记信息,机器学习的任务和分为两大类:监督学习(Supervised Learning)和非监督学习(Unsupervised Learning)。对于监督学习任务,我们明确得知道数据具有某些特点或者事先已经知道了样本将会属于什么类别,例如将西瓜分为“好瓜”与“坏瓜”,根据历史房价来预测未来房价;而对非监督学习任务,我们事先也不知道算法所产生的结果所具有的特点,例如对西瓜做聚类(Clusting)后,可能将西瓜分为“浅色瓜”和“深色瓜”等我们事先不知道的概念。监督学习有两种典型的任务:分类(Classification)和回归(Regression)。如果我们希望预测的是离散值,如“好瓜”或“坏瓜”、“盈利”或“亏损”等,那么该任务为分类任务;如果我们希望预测的是连续值,如在未来某个时间节点的房价、股票价格,那么该任务为回归任务。
线性回归(Linear Regression)
线性模型是一种简单、易于建模的模型,我们可以根据已有数据学习得到线性函数中的参数。得到参数的过程叫做线性回归(Linear Regression)。
现在假设我们得到了房产面积和房价的数据,而希望预测某个面积房产的房价。首先,我们需要根据已有的数据估计出模型的函数表达式。为了直观显示房产面积和房价的关系,我们可以将房价的数据绘制出来,观察数据间的关系。
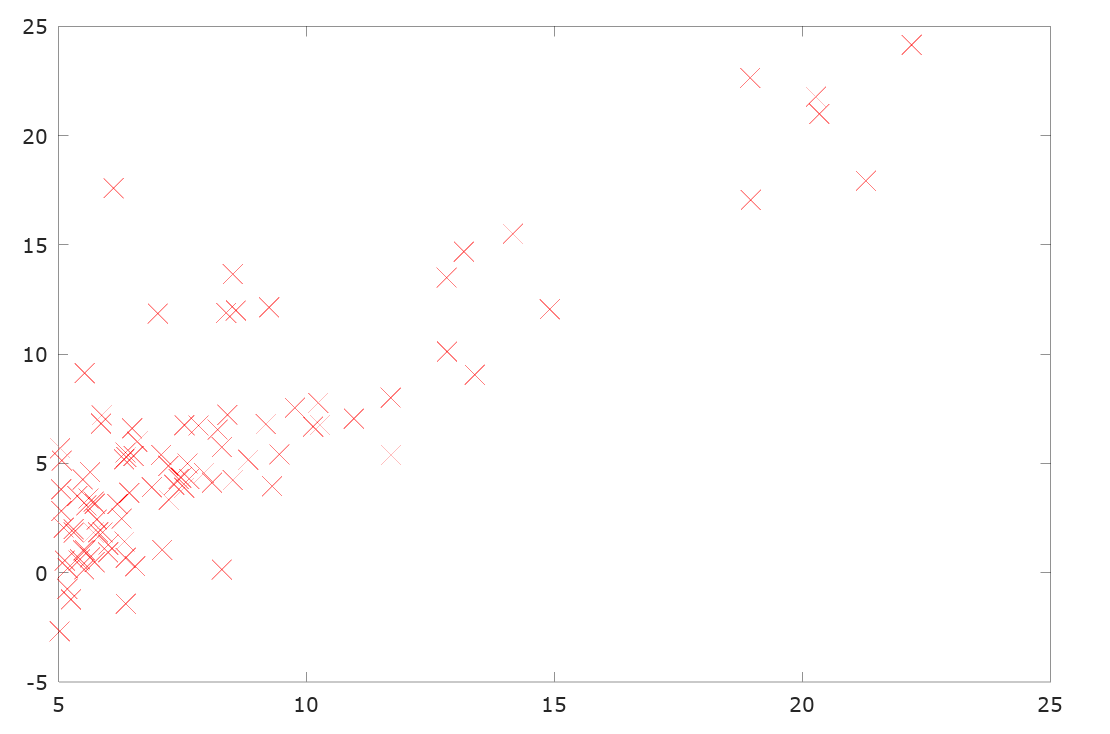
根据住房面积和房价之间的散点图,我们可以认为面积和房价成线性关系,即可以假设房价 y 和面积 x 的函数关系为:
$$ h_{\theta}(x) = \theta_0 + \theta_1x $$
其中 $x$ 模型的属性。
之后,我们就需要通过“学习”已有的数据,得到函数用得系数值。
成本函数(Cost Function)
在实现“回归”之前,我们将 Cost Function 定义为:
$$ J( \theta_0 , \theta_1 ) = \frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x_i) - y_i)^2 $$
这个函数定义了使用现有模型得出的 m 个预测值和实际值的均方误差(square loss)的平均值,而前面的 $\frac{1}{2}$ 则是为了之后的处理方便而添加的。
所以,我们的“回归”过程的目的,就是通过对“学习数据”的学习,得到一个模型,是得 Cost Function 的值最小。
梯度下降(Gradient Descent)
在机器学习中,常用梯度下降(Gradient Descent)的方法,通过不断迭代,学习得到使得 $J(\theta_0, \theta_1)$ 最小的 $\theta_0$ 和 $\theta_1$ 的值。
梯度下降方法的基本过程可以用伪代码来表示:
repeat until converage {
$$\theta_0 = \theta_0 - \alpha\sum_{i=1}^{m}(h_\theta(x_i) - y_i)$$
$$\theta_1 = \theta_1 - \alpha\sum_{i=1}^{m}((h_\theta(x_i) - y_i)x_i)$$
}
要注意的是,$\theta_0$和$\theta_1$必须要被同步更新,否则会导致算法出错。
我们可以研究下,为什么通过梯度下降的方式可以最终迭代到最优点。以一个简单的二次函数为例:
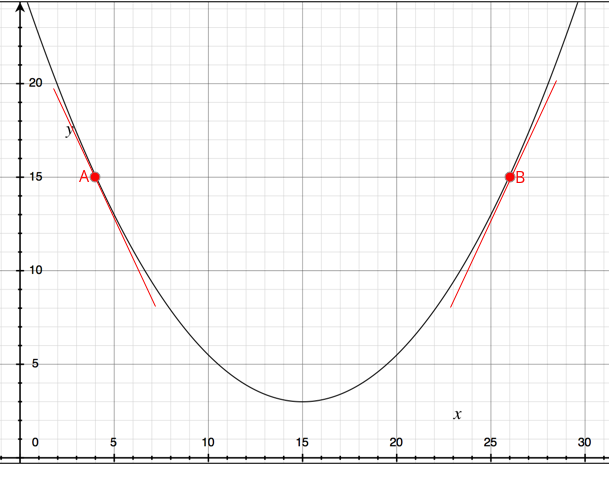
假设我们从 A 点开始使用梯度下降的方法迭代,该函数在 A 点的导数小于零,所以在梯度下降的过程中,$\theta = \theta - \alpha\frac{\mathrm d}{\mathrm d x}J(x)$ 会使得 $\theta$ 不断向右逼近,从而接近最低点。在 B 点同理可得,在梯度下降的过程中,$\theta$ 会不断向左逼近,靠近最低点。
在梯度下降的迭代过程中,我们通过选择不同的 $\alpha$ 值来控制 $\theta$ 变化的幅度或大小。当 $\theta$ 越小时,算法迭代的过程就以越小的步伐(更高的精度)来逼近最优点。所以,$\alpha$ 被称为 Learning Rate。
当 $\alpha$ 足够小的时候,梯度下降算法一定会最终抵达最优点。而且在迭代过程中不需要改变 $\alpha$ 的值,算法最终一定会收敛。这在数学上已经得到了证明。
但是要注意,梯度下降算法最终找到的是局部最优点,而不一定是全局最优点。
多元线性回归(Linear Regression with Multiple Variables)
在单变量线性回归问题中,我们假设模型只有一个属性。而在多元线性回归问题中,我们认为模型有多个属性。例如,在之前提到的预测房价的问题中,房价可能不仅仅有房产的面积所决定,还会被房产的年代、地段等因素影响。
在队员线性回归问题中,我们用变量 n 来代表模型属性的个数,$x^{(i)}$ 是一个行向量表示第 i 个训练样本的属性集,$x_j^{(i)}$ 表示第 i 个训练样本的第 j 个属性的值。
我们令 $x_0=1$ ,那么我们的模型和定义为:
$$h_{\theta}(x) = \theta_0 + {\theta_1}x_1 + {\theta_2}x_2 + \cdots + {\theta_n}x_n$$
即:
$$ h_{\theta}(x) = {\theta}^{T}x $$
其中:
$ {\theta^{T}} = [\theta_0, \theta_1, \cdots, \theta_n], x^{T} = [1, x_1, x_2, \cdots, x_n] $
现在我们在多元线性回归问题中使用梯度下降方法学习得到模型参数的过程可以写为:
repeat until converage {
$$ \theta_{j} = \theta_{j} - \alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)} - y^{(i)})x_j^{(i)}) $$
$$j = 1 \cdots n$$
}
注意,各参数必须同步更新。
加速收敛方法
在课程中,吴恩达教授还介绍了几种可以加速梯度下降过程的方法,分别是:Feature Scaling, Mean Normalization 和 选择 Learning Rate 的方法。
Feature Scaling
Feature Scaling 的主要原理是各个模型在数值上处于同一个“范围”,如都在$[0, 1]$这个范围。在预测房价的例子中,我们假设房产有属性:房产面积 $x_1 \in [0, 2000]$, 卧室数目 $x_2 \in [0, 5]$ 。这两个属性不在同一个数量级,那么在梯度下降的迭代过程中,可能出现算法收敛过慢,收敛路径复杂等问题。
为了解决这个问题,我们使用 Feature Scaling 方法,使得:
$$x_1 = \frac{x_1}{2000}$$ $$x_2 = \frac{x_2}{5}$$
或者我们使用 Mean Normalization 方法。令 $\mu_i = mean(x_i)$ , 有:
$$x_i = \frac{x_i - \mu_i}{max(x_i) - min(x_i)}$$
通过这两种方法,我们可以将所有属性在数值上属于同一范围,从而可以显著梯度下降的迭代速度。
选择合理的 Learning Rate
另外一种保证算法收敛的方式就是要选择一个大小合适的 Learning Rate。因为如果 $\alpha$ 过小,那么算法会收敛过慢;如果 $aplha$ 过大,可能导致算法无法保证在每次迭代使得参数减小。
我们可以将使用不同 Learning Rate 的迭代过程用可视化的方式表示出来,通过这种更形象的方式选择合适的 Learning Rate。
多项式回归(Polynomial Regression)
我们可以将多个属性组合成一个新的属性用于对模型参数的预测,例如将房产的地基长度x1和地基宽度x2组合为房产面积x3。
当我们的训练数据不能很好得用线性函数描述时,我们可以考虑使用二次或三次函数。
Normal Equation
在线性回归的问题中,我们的目的是通过学习训练数据,得到新的参数 $\theta$ 使得 $J(\theta)$ 最小。体用微积分的知识,我们可以对 $J(\theta)$ 中的 $\theta_0$ , $\theta_1$ 等分别求偏导数,并同时令偏导数等于0,即可算出使得 $J(\theta)$ 最小的参数值。
结论: 当 $\theta = (X^{T}X)^{-1}X^{T}y$时,$J(\theta)$ 最小。
我们对比梯度下降和 Normal Equation 方法:
| 梯度下降 | Normal Equation |
| 需要选择合适的 Learning Rate | 不需要选择Learning Rate |
| 需要多次迭代 | 不需要迭代 |
| 时间复杂度 O(kn^2) | 时间复杂度 O(n^3) |
| 在样本数量很大时,很有效 | 样本数量很大时,效率很低 |
参考文献
- 机器学习 周志华
- Machine Learning Stanford