$ kubectl describe deployment nginx-deployment ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- ... Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1 Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2 Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2 Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1 Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3 Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0
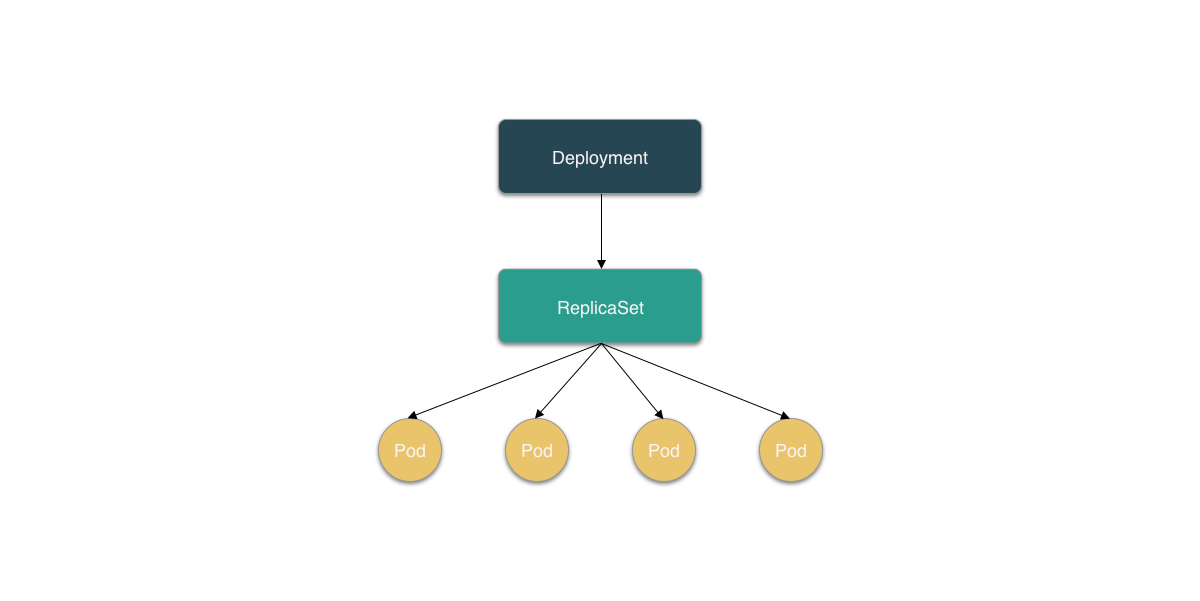
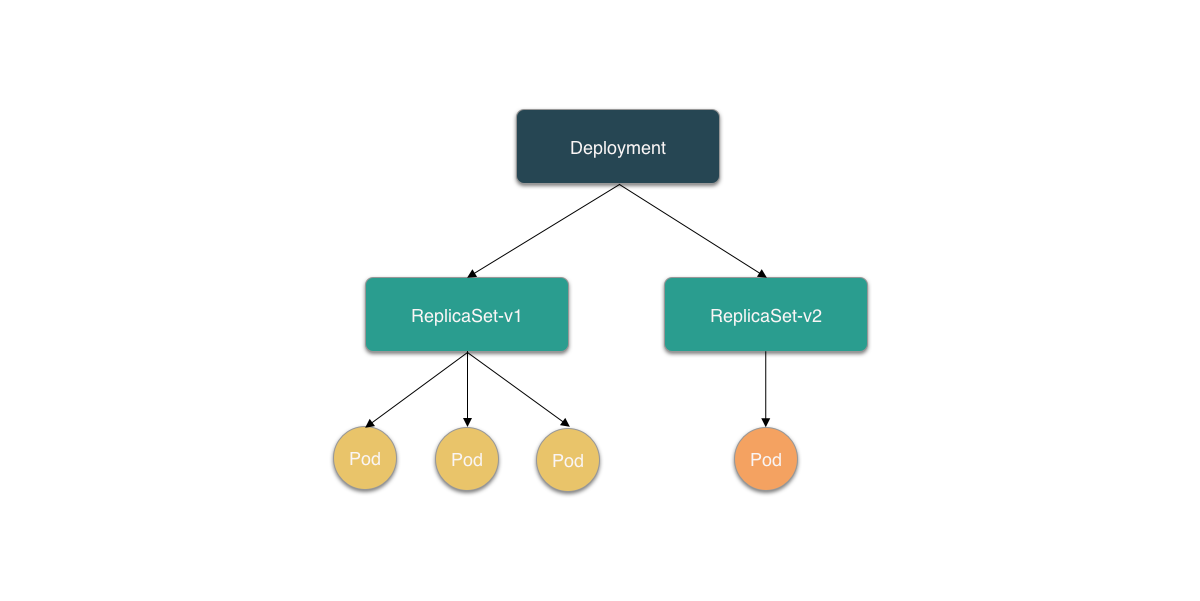
可以看到当修改 PodTemplate 后,Deployment Controller 会使用这个新的 PodTemplate 创建一个新的 ReplicaSet,它初始的副本数是 0。然后 Deployment Controller 开始将新的 ReplicaSet 所控制的 Pod 副本数由 0 个变成 1 个,即:“水平拓展”出一个副本;接着又将旧的 ReplicaSet 所控制的 Pod 副本数减少一个,即:“水平收缩”。如此交替进行,最后新的 ReplicaSet 所管理的 Pod 个数上升为 4,而旧的 ReplicaSet 所管理的 Pod 个数收缩为 0 个。
这样,将集群中正在运行的多个 Pod 版本,交替逐一升级更换的过程就是“滚动更新”。更新结束后,可以查看新、旧两个 ReplicaSet 的状态:
1 2 3 4 5
$ kubectl get rs NAME DESIRED CURRENT READY AGE nginx-deployment-1764197365 4 4 4 6s nginx-deployment-3167673210 0 0 0 30s
滚动更新有很明显的好处。比如当新的 Pod 因为故障无法启动时,“滚动更新”就会停止,允许开发者介入。而此时应用本身还是有两个旧版本的 Pod 在线,所以服务不会受到太大的影响。当然这也要求开发者一定要使用 Health Check 检查应用的运行状态,而不是依赖于容器的 Running 状态。此外,Deployment Controller 还会保证在任何时间窗口内,只有指定比例的新 Pod 被创建,及指定比例的旧 Pod 处于离线状态。这两个比例的默认值均为 25%,且可以在 spec.rollingUpdateStrategy 中配置:
// syncDeployment will sync the deployment with the given key. // This function is not meant to be invoked concurrently with the same key. func(dc *DeploymentController)syncDeployment(key string)error { namespace, name, err := cache.SplitMetaNamespaceKey(key) if err != nil { return err } deployment, err := dc.dLister.Deployments(namespace).Get(name) if errors.IsNotFound(err) { klog.V(2).Infof("Deployment %v has been deleted", key) returnnil } if err != nil { return err } d := deployment.DeepCopy() // List ReplicaSets owned by this Deployment, while reconciling ControllerRef // through adoption/orphaning. rsList, _ := dc.getReplicaSetsForDeployment(d) // List all Pods owned by this Deployment, grouped by their ReplicaSet. // Current uses of the podMap are: // // * check if a Pod is labeled correctly with the pod-template-hash label. // * check that no old Pods are running in the middle of Recreate Deployments. podMap, _ := dc.getPodMapForDeployment(d, rsList) if d.Spec.Paused { return dc.sync(d, rsList) } scalingEvent, err := dc.isScalingEvent(d, rsList) if err != nil { return err } if scalingEvent { return dc.sync(d, rsList) } switch d.Spec.Strategy.Type { case apps.RecreateDeploymentStrategyType: return dc.rolloutRecreate(d, rsList, podMap) case apps.RollingUpdateDeploymentStrategyType: return dc.rolloutRolling(d, rsList) } return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type) }
// sync is responsible for reconciling deployments on scaling events or when they // are paused. func(dc *DeploymentController)sync(d *apps.Deployment, rsList []*apps.ReplicaSet)error { newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false) if err != nil { return err } if err := dc.scale(d, newRS, oldRSs); err != nil { // If we get an error while trying to scale, the deployment will be requeued // so we can abort this resync return err } allRSs := append(oldRSs, newRS) return dc.syncDeploymentStatus(allRSs, newRS, d) }
func(dc *DeploymentController)scale(deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet)error { // If there is only one active replica set then we should scale that up to the full count of the // deployment. If there is no active replica set, then we should scale up the newest replica set. if activeOrLatest := deploymentutil.FindActiveOrLatest(newRS, oldRSs); activeOrLatest != nil { if *(activeOrLatest.Spec.Replicas) == *(deployment.Spec.Replicas) { returnnil } _, _, err := dc.scaleReplicaSetAndRecordEvent(activeOrLatest, *(deployment.Spec.Replicas), deployment) return err }
// If the new replica set is saturated, old replica sets should be fully scaled down. // This case handles replica set adoption during a saturated new replica set. if deploymentutil.IsSaturated(deployment, newRS) { for _, old := range controller.FilterActiveReplicaSets(oldRSs) { if _, _, err := dc.scaleReplicaSetAndRecordEvent(old, 0, deployment); err != nil { return err } } returnnil } }
// There are old replica sets with pods and the new replica set is not saturated. // We need to proportionally scale all replica sets (new and old) in case of a // rolling deployment. if deploymentutil.IsRollingUpdate(deployment) { allRSs := controller.FilterActiveReplicaSets(append(oldRSs, newRS)) allRSsReplicas := deploymentutil.GetReplicaCountForReplicaSets(allRSs)
// Number of additional replicas that can be either added or removed from the total // replicas count. These replicas should be distributed proportionally to the active // replica sets. deploymentReplicasToAdd := allowedSize - allRSsReplicas
// The additional replicas should be distributed proportionally amongst the active // replica sets from the larger to the smaller in size replica set. Scaling direction // drives what happens in case we are trying to scale replica sets of the same size. // In such a case when scaling up, we should scale up newer replica sets first, and // when scaling down, we should scale down older replica sets first. var scalingOperation string switch { case deploymentReplicasToAdd > 0: sort.Sort(controller.ReplicaSetsBySizeNewer(allRSs)) scalingOperation = "up"
case deploymentReplicasToAdd < 0: sort.Sort(controller.ReplicaSetsBySizeOlder(allRSs)) scalingOperation = "down" }
调用 FilterActiveReplicaSets 查询所有活跃的 ReplicaSet;
调用 GetReplicaCountForReplicaSets 计算当前 Deployment 对应 ReplicaSet 持有的全部 Pod 副本个数;
根据 Deployment 配置的 maxSurge 和 replicas 计算允许创建的 Pod 数量;
// Iterate over all active replica sets and estimate proportions for each of them. // The absolute value of deploymentReplicasAdded should never exceed the absolute // value of deploymentReplicasToAdd. deploymentReplicasAdded := int32(0) nameToSize := make(map[string]int32) for i := range allRSs { rs := allRSs[i]
// Estimate proportions if we have replicas to add, otherwise simply populate // nameToSize with the current sizes for each replica set. if deploymentReplicasToAdd != 0 { proportion := deploymentutil.GetProportion(rs, *deployment, deploymentReplicasToAdd, deploymentReplicasAdded)
// Update all replica sets for i := range allRSs { rs := allRSs[i]
// Add/remove any leftovers to the largest replica set. if i == 0 && deploymentReplicasToAdd != 0 { leftover := deploymentReplicasToAdd - deploymentReplicasAdded nameToSize[rs.Name] = nameToSize[rs.Name] + leftover if nameToSize[rs.Name] < 0 { nameToSize[rs.Name] = 0 } }
// TODO: Use transactions when we have them. if _, _, err := dc.scaleReplicaSet(rs, nameToSize[rs.Name], deployment, scalingOperation); err != nil { // Return as soon as we fail, the deployment is requeued return err } }
// rolloutRecreate implements the logic for recreating a replica set. func(dc *DeploymentController)rolloutRecreate(d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID][]*v1.Pod)error { // Don't create a new RS if not already existed, so that we avoid scaling up before scaling down. newRS, oldRSs, _ := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false) allRSs := append(oldRSs, newRS) activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
// scale down old replica sets. scaledDown, _ := dc.scaleDownOldReplicaSetsForRecreate(activeOldRSs, d) if scaledDown { // Update DeploymentStatus. return dc.syncRolloutStatus(allRSs, newRS, d) }
// Do not process a deployment when it has old pods running. if oldPodsRunning(newRS, oldRSs, podMap) { return dc.syncRolloutStatus(allRSs, newRS, d) }
// If we need to create a new RS, create it now. if newRS == nil { newRS, oldRSs, _ = dc.getAllReplicaSetsAndSyncRevision(d, rsList, true) allRSs = append(oldRSs, newRS) }
// scale up new replica set. if _, err := dc.scaleUpNewReplicaSetForRecreate(newRS, d); err != nil { return err }
if util.DeploymentComplete(d, &d.Status) { if err := dc.cleanupDeployment(oldRSs, d); err != nil { return err } }
func(dc *DeploymentController)reconcileOldReplicaSets(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, deployment *apps.Deployment)(bool, error) { oldPodsCount := deploymentutil.GetReplicaCountForReplicaSets(oldRSs) if oldPodsCount == 0 { // Can't scale down further returnfalse, nil }
allPodsCount := deploymentutil.GetReplicaCountForReplicaSets(allRSs) klog.V(4).Infof("New replica set %s/%s has %d available pods.", newRS.Namespace, newRS.Name, newRS.Status.AvailableReplicas) maxUnavailable := deploymentutil.MaxUnavailable(*deployment) minAvailable := *(deployment.Spec.Replicas) - maxUnavailable newRSUnavailablePodCount := *(newRS.Spec.Replicas) - newRS.Status.AvailableReplicas maxScaledDown := allPodsCount - minAvailable - newRSUnavailablePodCount if maxScaledDown <= 0 { returnfalse, nil } oldRSs, cleanupCount, err := dc.cleanupUnhealthyReplicas(oldRSs, deployment, maxScaledDown) if err != nil { returnfalse, nil } klog.V(4).Infof("Cleaned up unhealthy replicas from old RSes by %d", cleanupCount)
// Scale down old replica sets, need check maxUnavailable to ensure we can scale down allRSs = append(oldRSs, newRS) scaledDownCount, err := dc.scaleDownOldReplicaSetsForRollingUpdate(allRSs, oldRSs, deployment) if err != nil { returnfalse, nil } klog.V(4).Infof("Scaled down old RSes of deployment %s by %d", deployment.Name, scaledDownCount)