函数装饰器(Function decotator)让我们可以通过在代码中“标记”函数来增强它的行为。这是一种很强大的特性,但是充分理解它需要首先理解闭包(clousure)。
Python 中的最新的被保留的关键字之一是 nonlocal,在 Python 3.0 中被引入。如果你仅仅使用以类为中心的面向对象编程方法的话,你可能从来都没有使用过这个关键字。然而,如果你想实现你自己的函数装饰器,你必须完全理解闭包,那么这时,nonlocal 关键字就是必须的。
除了在装饰器中的应用外,闭包还可以再异步编程中实现回调(callback),也可以在函数式编程中发挥作用。
为了解释装饰器究竟如何工作,我们首先需要解释:
Python 怎样处理装饰器的语法
Python 怎么确定某个变量是否为局部变量
闭包如何工作
nolocal 解决了什么问题
以这四个问题为基础,我们继续研究其他装饰器主题:
实现一个运行良好的装饰器
标准库中有趣的装饰器
实现一个参数化的装饰器
我们从一个简单的介绍开始。
装饰器 101 装饰器是一个将另外一个函数作为参数的可调用对象(callable),作为参数的函数为称为 decorated function。装饰器可能对函数做一些特殊处理,然后再返回或者用另外一个函数来替换它。
换句话说,假设有一个叫做decorate的装饰器,下面这段代码:
1 2 3 @decorate def target () : print("running target()" )
和这样写有完全一致的结果:
1 2 3 4 def target () : print("running target()" ) target = decorate(target)
这两个代码片段的结尾都是一样的,target 并不一定要指向原来的 target 函数,而是指向 decorate(target) 返回的函数。我们可以确认一下:
1 2 3 4 5 6 7 8 9 10 11 12 def deco (func) : def inner () : print("running inner()" ) return inner @deco def target () : print("running target()" ) >>> target()running inner() >>> target<function __main__.deco.<locals>.inner>
严格来说,装饰器只是一种语法糖。就像我们看到的,你可以简单地把装饰器当做一个可调用对象,传入一个函数作为参数。
总结一下:首先,装饰器可以用另外一个函数来代替被装饰的函数;其次,装饰器在模块被加载时理解执行。
Python 执行装饰器的时机 装饰器的一个关键特性是他们在被装饰函数(decorated function)被定义后立即执行。这通常发生在导入时间(import time)。考虑下面的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 """registraion.py""" registry = [] def register (func) : print("running register(%s)" % func) registry.append(func) return func @register def f1 () : print("running f1()" ) @register def f2 () : print("running f2()" ) def f3 () : print("running f3()" ) def main () : print("running main()" ) print("registry ->" , registry) f1() f2() f3() if __name__ == "__main__" : main()
registry 保存了被 @register 装饰的函数的引用装饰器 register 接受一个函数作为参数
f1 和 f2 被 @register 装饰,f3 没有被装饰main 函数打印了 registry,然后调用了 f1, f2, f3main 仅仅在运行该脚本时才会被调用
运行这个脚本的输出是:
1 2 3 4 5 6 7 8 $ python3 registration.py running register(<function f1 at 0x10d318d08>) running register(<function f2 at 0x10d318c80>) running main() registry -> [<function f1 at 0x10d318d08>, <function f2 at 0x10d318c80>] running f1() running f2() running f3()
注意到 register 在模块中其他函数运行前执行了两次。当 register 被调用时,它接受了一个被装饰的函数对象作为参数,如:<function f1 at 0x10d318d08>。
模块被加载后,registry 保存了两个被装饰函数 f1,f2的引用。这些函数,还有 f3 只有在 main 函数显式调用后才执行。如果 registration.py 被导入(而不是执行脚本),那么输出为:
1 2 3 > >> import registration running register(<function f1 at 0x10d318d08>) running register(<function f2 at 0x10d318c80>)
这时,如果我们查看 registry,可以看到:
1 2 > >> registration.registry [<function f1 at 0x10d318d08>, <function f2 at 0x10d318c80>]
上面的例子是为了强调函数装饰器(function decorators)在模块被导入的时候马上执行,但是被装饰的函数(decorated function) 仅仅在他们被显式调用后才执行。这就是 Python 老炮们常说的 导入时间(import time) 和 运行时间(runtime)。
考虑装饰器在真实代码里的普遍使用方式,上面的例子有两个问题:
装饰器(decorator)和被装饰函数(decorated function)被定义在了同一个模块中。一个真实的装饰器通常被定义在单独的模块中并修饰其他模块中的函数。
register 装饰器返回了被当做参数传入的同一个函数。在实践中,大多数装饰器都定义一个内部函数并返回它。
尽管 register 装饰器返回了没有被修改的函数,这样的方法其实是有用武之地的。许多 Python Web Framework 都使用相似的方法来将函数添加到某注册机制中,例如,一个注册机将 URL 映射到生成 HTTP 响应的函数。这样的注册过程可能不会修改被装饰函数。
使用装饰器重构策略模式 首先看一段使用函数是“first-class object”这一特点实现策略模式的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 from collections import namedtupleCustomer = namedtuple("Customer" , "name fidelity" ) class LineItem : def __init__ (self, product, quantity, price) : self.product = product self.quantity = quantity self.price = price def total (self) : return self.price * self.quantity class Order : def __init__ (self, customer, cart, promotion=None) : self.customer = customer self.cart = list(cart) self.promotion = promotion def total (self) : if not hasattr(self, "__total" ): self.__total = sum(item.total() for item in self.cart) return self.__total def due (self) : if self.promotion is None : discount = 0 else : discount = self.promotion(self) return self.total() - discount def __repr__ (self) : fmt = "<Order total: {:2f}> due: {:.2f}" return fmt.format(self.total(), self.due()) def fidelity_promo (order) : """5% discount for customers with 1000 or more fidelity points""" return order.total() * .05 if order.customer.fidelity >= 1000 else 0 def bulk_item_promo (order) : """10% discount for each LineItem with 20 or more units""" discount = 0 for item in order.cart: if item.quantity >= 20 : discount += item.total() * .1 return discount def large_order_promo (order) : """7% discount for orders with 10 or more distince items""" distinct_items = { item.product for item in order.cart } if len(distinct_items) >= 10 : return order.total() * .07 return 0 promos = [fidelity_promo, bulk_item_promo, large_order_promo] def best_promo (order) : return max(promo(order) for promo in promos)
上面这段代码的只要问题在于函数名的重复,每个计算优惠的策略都以_promo结尾。best_promo函数使用promos列表来决定最大的优惠力度。这种命名上的重复的问题在于,当新添加了计算优惠的函数时,我们很可能会忘记将它添加到promos中。这种情况下,best_promo会忽略新的优惠计算函数而产生 bug。下面的代码中,我们使用装饰器重构代码来解决这个问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 promos = [] def promotion (promo_func) : promos.append(promo_func) return promo_func @promotion def fidelity (order) : """5% discount for customers with 1000 or more fidelity points""" return order.total() * .05 if order.customer.fidelity >= 1000 else 0 @promotion def bulk_item (order) : """10% discount for each LineItem with 20 or more units""" discount = 0 for item in order.cart: if item.quantity >= 20 : discount += item.total() * .1 return discount @promotion def large_order (order) : """7% discount for orders with 10 or more distince items""" distinct_items = { item.product for item in order.cart } if len(distinct_items) >= 10 : return order.total() * .07 return 0 def best_promo (order) : """Select best discount available""" return max(promo(order) for promo in promos)
这个解决方案的有点在于:
计算优惠的策略函数不再需要使用特殊的名字(比如,不在需要以_promo结尾)。
装饰器@promotion强调了函数的作用,而且可以很容易地暂时取消一种优惠策略:注释掉装饰器就好。
计算优惠的策略可能被定义在其他模块,或者系统的任何地方。不管函数被定义在哪里,都知道用@promotion修饰就好了。
大多数装饰器(decorator)都会改变被装饰函数(decorated function)。它们通过定义并返回一个内部函数来替代被装饰函数。使用了内部函数的代码大多依赖于闭包(closure)来正确运行。为了理解闭包,我们得先退后一步,看看 Python 中的变量作用域。
变量作用域的规则 在下面的例子中,我们定义并测试了一个读取两个变量的函数:一个局部变量a,被定义为函数的参数;一个没有被定义在函数内的变量b。
1 2 3 4 5 6 7 8 9 10 >>> def f1 (a) : print(a) print(b) >>> f1(3 )3 Traceback (most recent call last): File "<stdin>" , line 1 , in <module> File "<stdin>" , line 3 , in f1 NameError: global name 'b' is not defined
我们对于代码运行出现的错误不会感到意外。如果我们首先为全局变量b赋值,然后再调用f1,代码就可以正确工作了:
下面,来看一个可能会让你吃惊的例子。
1 2 3 4 5 6 7 8 9 10 11 12 >>> b = 6 >>> def f2 (a) : print(a) print(b) b = 9 >>> f2(3 )3 Traceback (most recent call last): File "<stdin>" , line 1 , in <module> File "<stdin>" , line 3 , in f2 UnboundLocalError: local variable 'b' referenced before assignment
注意到 3 被正确打印了,这说明 print(a) 被执行了。但是第二句 print(b) 没有运行。很多人有会很意外,认为 6 应该被打印,因为局部变量 b 在全局变量 b 被打印之后被赋值。
但事实上,当 Python 编译函数时,决定 b 是局部变量,因为它在函数内被赋值了。生成的二进制字节码也反映了这一点,b 会被从本地环境中获取。之后,当试图获取局部变量 b 的值得时候,会发现 b 未被绑定。
这并不是一个 bug,而是一个设计选择:Python 不要求用户声明变量,但是假设在函数内被赋值的变量是局部变量。这就比 JavaScript 强很多了,JavaScript 也不要求声明变量,但是如果你忘记了用 var 来声明局部变量,你可能会误用一个全局变量。
如果我们希望解析器将在函数内被赋值的变量 b 作为全局变量,我们使用 global 关键字来声明:
1 2 3 4 5 6 7 8 9 10 11 >>> def f3 (a) : global b print(a) print(b) b = 9 >>> f3(3 )3 6 >>> b9
闭包(Closure) 在技术博客里面,闭包常常与匿名函数混淆。这是一个历史原因:在使用匿名函数之前,在函数中定义另外一个函数并不常见。闭包仅仅在你定义嵌套函数的时候才有意义。所以很多人同时学习这两个概念。
实际上,闭包是一个拥有拓展作用域的函数,闭包的作用域包含了在函数内被引用但是却没有被定义在函数中的非全局变量。
这个概念不太好懂,我们最好还是通过例子来理解它。
考虑一个计算一个增长序列均值的函数avg,例如股票在整个历史中的平均价格。每天都会有新的价格加入序列,函数avg会计算到目前为止的平均值。
1 2 3 4 5 6 >>> avg(10 )10 >>> avg(11 )10.5 >>> avg(12 )11.0
avg 如何保存之前的值呢?
我们首先看一个使用类来实现的版本:
1 2 3 4 5 6 7 8 9 class Averager () : def __init__ (self) : self.series = [] def __call__ (self, new_value) : self.series.append(new_value) total = sum(self.series) return total / len(self.series)
Averager 类的实例是可调用的:
1 2 3 4 5 6 7 >>> avg = Averager()>>> avg(10 )10.0 >>> avg(11 )10.5 >>> avg(12 )11.0
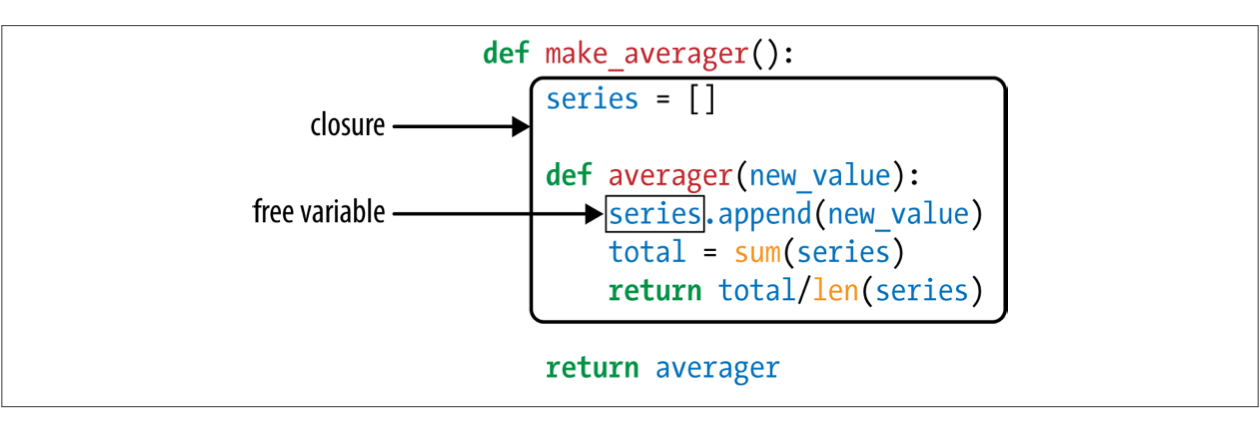
我们再来看一个函数式的例子,它使用了高阶函数make_averager。
1 2 3 4 5 6 7 8 9 def make_averager () : series = [] def averager (new_value) : series.append(new_value) total = sum(series) return total / len(series) return averager
被调用时,make_averager 返回一个 averager 函数对象。每次 averager 被调用,它将被传入的参数添加到 series 中,并且计算现在的平均值。
1 2 3 4 5 6 7 >>> avg = make_averager()>>> avg(10 )10.0 >>> avg(11 )10.5 >>> avg(12 )11.0
注意这两种方案的相似之处:我们调用 Averager() 或者 make_averager() 来得到一个可调用对象 avg,它会更新历史数据并计算目前的平均值。
Averager 中的 avg 保存历史记录的方式很明显:self.series 实例属性。但是make_averager 中的 avg 是如何找到 series 的呢?
注意到 series 是 make_averager 的局部变量,因为它在 make_averager 中被初始化。但是当调用 avg(10)时,make_averager 已经返回了,它的局部作用域已经被回收。
在 averager 中,series 是自由变量(free variable),这个属于的意思是没有被绑定到该函数局部作用域中的变量。
检查被返回的 averager 对象,我们可以看到 Python 是如果将局部变量和自由变量保存在 __code__ 属性中的。__code__ 属性代表了函数内容被编译后的结果。
1 2 3 4 >>> avg.__code__.co_varnames('new_value' , 'total' ) >>> avg.__code__.co_freevars('series' ,)
对 series 的绑定被保存在函数的 __closure__ 属性中。avg.__clousre__中的每个元素对应 avg.__code__.co_freevars 中的一个名字。这些元素被称为 cells,它们有保存了真实值的属性 cell_contents。
1 2 3 4 5 6 >>> avg.__code__.co_freevars('series' ,) >>> avg.__closure__(<cell at 0x110f4cc78 : list object at 0x11104fb88 >,) >>> avg.__closure__[0 ].cell_contents[10 , 11 , 12 ]
总结一下:闭包是持有了对自由变量绑定的函数,自由变量在函数被定义时就存在了,所有它们可以在作用域消失的时候仍然可以被使用。
注意只有当一个函数被嵌套到另外一个函数内时,它才需要处理外部作用域的非全局变量。
nonlocal 修饰符 我们之前实现的 make_averager 不太高效。我们在数组中保存了所有出现过的值,然后在每次调用 averager 时会计算所有值的和。一个更好的实现应该仅仅保存总的和,以及到目前为止元素的个数,然后利用这两个值来计算平均值。
下面的代码是错误的,我们可以看看它错在哪里:
1 2 3 4 5 6 7 8 9 10 def make_averager () : count = 0 total = 0 def averager (new_value) : count += 1 total += new_value return total / count return averager
如果我们运行这段代码,会打印出错误信息:
1 2 3 4 >>> avg = make_averager()>>> avg(10 )Traceback (most recent call last): UnboundLocalError: local variable 'count' referenced before assignment
出错的原因在于, 当 count 是数字或不可变类型时,count += 1 实际上相当于 count = count + 1。所以我们实际上是在 averager 的函数内部为 count 赋值,那么这一步就将 count 变为了局部变量。total 也有同样的问题。
我们在之前的例子总没有这样的问题,因为我们从来没有为 series 赋值,我们仅仅通过调用 series.append 在增加元素,并计算 sum 和 len。我们利用了列表是可变类型的特点。
但是对于像数字、字符、tuple这样的不可变类型,我们只可以读数据,但是永远都不能够更新它。如果我们试着重新绑定它们,像 count = count + 1,那么你就是在隐式地创建局部变量 count。这样的话,count 就不再是自由变量,所以它没有被保存在闭包中。
为了解决这个问题,Python 3 引入了新的关键字 nonlocal。它让我们将变量标记为自由变量,即使该变量在函数内部被赋值。如果给 nonlocal 变量赋值,那么在闭包中保存的变量绑定也会改变。所以,make_averager 的正确是实现应该是:
1 2 3 4 5 6 7 8 9 10 11 def make_averager () : count = 0 total = 0 def averager (new_value) : nonlocal count, total count += 1 total += new_value return total / count return averager
现在,我们介绍了 Python 中的闭包,我们可以利用内嵌函数来实现装饰器了。
实现一个简单的装饰器 下面,我们实现一个为函数的每次调用计时的装饰器,使某函数在每次被调用后就打印函数调用的时间、传入的参数、调用的返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 import timedef clock (func) : def clocked (*args) : t0 = time.perf_counter() result = func(*args) elapsed = time.perf_counter() - t0 name = func.__name__ arg_str = ', ' .join(repr(arg) for arg in args) print("[%0.8fs] %s(%s) -> %r" % (elapsed, name, arg_str, result)) return result return clocked
我们定义了一个内嵌函数 clocked,它可以接受任意个数的参数
clocked 捕获了自由变量 funclock 会返回内嵌函数 clocked 来代替原来的函数
下面的代码使用了 clock 装饰器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import timefrom ex15 import clock@clock def snooze (seconds) : time.sleep(seconds) @clock def factorial (n) : return 1 if n < 2 else n * factorial(n - 1 ) if __name__ == "__main__" : print('*' * 40 , "Calling snooze(.123)" ) snooze(.123 ) print('*' * 40 , "Calling factorial(6)" ) print("6! =" , factorial(6 ))
上面代码的输出是:
1 2 3 4 5 6 7 8 9 10 **************************************** Calling snooze(.123) [0.12784183s] snooze(0.123) -> None **************************************** Calling factorial(6) [0.00000130s] factorial(1) -> 1 [0.00004024s] factorial(2) -> 2 [0.00006179s] factorial(3) -> 6 [0.00007902s] factorial(4) -> 24 [0.00009839s] factorial(5) -> 120 [0.00012213s] factorial(6) -> 720 6! = 720
它是怎么工作的呢 要知道代码:
1 2 3 @clock def factorial (n) : return 1 if n < 2 else n * factorial(n - 1 )
实际上是做的是:
1 2 3 4 def factorial (n) : return 1 if n < 2 else n * factorial(n - 1 ) factorial = clock(factorial)
在两个例子中,clock 将 factorial 作为参数,然后创建并返回 clocked 函数,最后,Python 解释器将 factorial 绑定到 clocked。实际上,如果我们检查 factorial 的 __name__ 属性,可以得到:
1 2 >>> clockdeco_demo.factorial.__name__ "clocked"
所以,factorial 实际上保存了指向 clocked 的引用。从现在开始,每次调用 factorial(n),实际上会执行的是 clocked。而 clocked 的执行步骤为:
记录初始时间 t0
调用原来的 factorial 函数,保存结果
计算得到结果的花费时间
格式化并打印收集到的数据
返回保存的计算结果
这是装饰器的典型的行为:它用接受相同参数的新的函数来代替被装饰的函数,并且在返回被装饰函数应该返回的结果的基础上,做额外的工作。
在上面例子中的装饰器有一些缺点:它不接受关键字参数,它覆盖了被装饰函数的 __name__ 和 __doc__ 属性。下面的例子中,我们使用 functools.wraps 装饰器将 func 的属性拷贝到 clocked 属性中。而且,新版本的装饰器也可以接受关键字参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import timeimport functoolsdef clock (func) : @functools.wraps(func) def clocked (*args, **kwargs) : t0 = time.time() result = func(*args, **kwargs) elapsed = time.time() - t0 name = func.__name__ arg_lst = [] if args: arg_lst.append(', ' .join(repr(arg) for arg in args)) if kwargs: pairs = ["%s=%r" % (k, w) for k, w in sorted(kwargs.items())] arg_lst.append(', ' .join(pairs)) arg_str = ', ' .join(arg_lst) print("[%0.8fs] %s(%s) -> %r" % (elapsed, name, arg_str, result)) return result return clocked
functools.wraps 仅仅是标准库中直接可用的装饰器之一。我们来研究两个 functools 提供的两个强大的装饰器 lru_cache 和 singleddispatch。
标准库中的装饰器 标准库中最有趣的两个装饰器是 lru_cache 和 singledispatch,它们都被被定义在 functools 中。
functools.lru_cache 是一个非常实用的装饰器,它实现了计算的记忆化。记忆化是通过将之前的计算结果缓存,从而避免重复计算的优化技术。LRU 是 Least Recently Used(最近最久未使用)的缩写,意思是通过丢弃暂时没有使用的单元来限制缓存的大小。
我们可以使用 lru_cache 来优化计算 Fibonacci 的递归函数。
1 2 3 4 5 6 7 8 9 10 11 from clockdeco2 import clock@clock def fibonacci (n) : if n < 2 : return n return fibonacci(n - 2 ) + fibonacci(n - 1 ) if __name__ == '__main__' : print(fibonacci(6 ))
这是一个非常低效的版本,这一点我们可以从它的输入信息看出来:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [0.00000119s] fibonacci(0) -> 0 [0.00000119s] fibonacci(1) -> 1 [0.00006604s] fibonacci(2) -> 1 [0.00000119s] fibonacci(1) -> 1 [0.00000095s] fibonacci(0) -> 0 [0.00000095s] fibonacci(1) -> 1 [0.00002599s] fibonacci(2) -> 1 [0.00004578s] fibonacci(3) -> 2 [0.00013208s] fibonacci(4) -> 3 [0.00000000s] fibonacci(1) -> 1 [0.00000095s] fibonacci(0) -> 0 [0.00000000s] fibonacci(1) -> 1 [0.00001907s] fibonacci(2) -> 1 [0.00003767s] fibonacci(3) -> 2 [0.00000119s] fibonacci(0) -> 0 [0.00000095s] fibonacci(1) -> 1 [0.00001907s] fibonacci(2) -> 1 [0.00000119s] fibonacci(1) -> 1 [0.00000000s] fibonacci(0) -> 0 [0.00000119s] fibonacci(1) -> 1 [0.00001907s] fibonacci(2) -> 1 [0.00003791s] fibonacci(3) -> 2 [0.00007606s] fibonacci(4) -> 3 [0.00013065s] fibonacci(5) -> 5 [0.00028324s] fibonacci(6) -> 8 8
代码的低效是很明显的,fibonacci(1) 被计算了8次,fibonacci(2) 被计算了5次。但是如果我们添加了 lru_cache,性能会得到很大提升。
1 2 3 4 5 6 7 8 9 10 11 12 13 import functoolsfrom clockdeco2 import clock@functools.lru_cache() @clock def fibnocci (n) : if n < 2 : return n return fibnocci(n - 2 ) + fibnocci(n - 1 ) if __name__ == "__main__" : print(fibnocci(6 ))
lru_cache 必须写成函数调用的形式,注意后面的括号。这是因为它可以接受配置信息。这是一个堆叠装饰器的例子,@lru_cacha() 修饰被 @clock 返回的函数
上面的代码将运行时间缩短了一半,消除了所有的重复计算
1 2 3 4 5 6 7 8 [0.00000119s] fibnocci(0) -> 0 [0.00000215s] fibnocci(1) -> 1 [0.00011992s] fibnocci(2) -> 1 [0.00000167s] fibnocci(3) -> 2 [0.00015306s] fibnocci(4) -> 3 [0.00000095s] fibnocci(5) -> 5 [0.00018692s] fibnocci(6) -> 8 8
在另一个测试中,计算 fibonacci(30) 没有使用 lru_cache 的版本需要调用 fibonacci 2,692,537 次,花费 17.7秒,而优化有的版本仅仅调用 31 次,仅仅花费 0.0005秒。
除了优化递归函数外,lru_cache 还可以被应用于从 Web 获取数据的应用程序。
我们可以通过传入两个可选参数来调整 lru_cache 的行为,它的完整函数名称为:
1 functools.lru_cache(maxsize=128 , typed=False )
maxsize 参数确定了最多有多少和单元可以被缓存,如果缓存被填满,旧的单元将被删除。为了性能考虑,maxsize 通常应该是 2 的幂。type 如果被设置为 True,不同的参数类型的结果就会被分开存储,例如传入 float 和 int 作为参数的 1.0 和 1 的两次计算结果会被分开存储。另外,应为 lru_cache 使用了 dict 来存储数据,字典的键是根据传入的参数来确定的,所以参数都必须 hashable。
Single Disptch 实现泛型函数 假设我们要开发一个调试 Web 应用程序的工具。我们希望为不同的 Python 对象生成不同的 HTML 文本。
我们可以从一个函数开始:
1 2 3 4 5 import htmldef htmlize (obj) : content = html.escape(repr(obj)) return "<pre>{}</pre>" .format(content)
这段代码可以作用与任何 Python 类型,但是我们想拓展它来为一些类型生成不同的文本:
str:将内嵌的换行符用 “<br >\n” 替换,使用 <p > 而不是 <pre >
int:用十进制和十六进制来显示数字
list: 输出一个 HTML 列表,根据不同元素类型来格式化每一行
我们希望的行为如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 >>> htmlize({1, 2, 3}) '<pre>{1, 2, 3}</pre>' >>> htmlize(abs) '<pre><built-in function abs></pre>' >>> htmlize("Heimlich & Co.\n- a game") '<p>Heimlich & Co.<br>\n- a game</p>' >>> htmlize(42) '<pre>42 (0x2a)</pre>' >>> print(htmlize(["alpha", 66, {3, 2, 1}])) <ul> <li><p>alpha</p></li> <li><pre>66 (0x42)</pre></li> <li><pre>{1, 2, 3}</pre></li> </ul>
因为 Python 中没有函数重载,我们不懂通过控制函数的类型来重载 htmlize。Python 中一种普遍的方式是将 htmlize 变为一个分发函数,也就是使用 if/elif/else 将操作分发到 htmlize_str, htmlize_int 等。这种方式是补课拓展的,随着不同类型操作的增加,我们代码中的 if/elif 也会越来越长,代码间的耦合度过于紧密了。
新的 functools.singledispatch 装饰器在 Python 3.4 中引入,它允许我们增加新的特化函数。如果我们用 @singledispatch 装饰一个函数,这个函数就变成了一个 generic function 泛型函数:用不同方法来解决相同问题的一组函数,它们根据参数的类型选择应该执行的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from functools import singledispatchfrom collections import absimport numbersimport html@singledispatch def htmllize (obj) : content = html.escape(repr(obj)) return "<pre>{}</pre>" .format(content) @htmllize.register(str) def _ (text) : content = html.escape(text).replace('\n' , '<br>\n' ) return '<p>{0}</p>' .format(content) @htmllize.resigter(numbers.Integral) def _ (n) : return '<pre>{0} (0x{0:x})</pre>' .format(n) @htmllize.register(tuple) @htmllize.register(abs.MutableSequence) def _ (seq) : inner = '</li>\n<li>' .join(htmlize(item) for item in seq) return '<ul>\n<li>' + inner + '</li>\n</ul>'
@singledispatch 标记了处理 object 的基函数每一种特化函数都用 @<base_function>.register(<type>) 来装饰,它们的函数名无关紧要,_是一个好的选择
我们也可以叠加多个装饰器来用一个函数来处理几种参数
如果可能的话,尽量使用抽象类型,如 numbers.Intergral 和 abs.MutableSequence,而不是具体类型如 int 或 list 来注册特化函数,这样,我们的函数可以支持更多的兼容类型。
我们可以使用 singledispatch 在系统的任意位置注册特化函数。如果我们在一个新的模块添加了新的自定义类型,我们可以直接在新的模块中添加处理该类型的代码。我们我也可为不是自己所写,也无权修改的函数添加自定义的实现。
singledispatch 的完整特性可以查看 PEP 443 - Single-dispatch generic functions
因为装饰器本质上是函数,所谓我们可以组合它们。
Stacked Decorators 当两个装饰器 @d2 和 @d1 依次作用于函数 f 后,结果其实就是 f = d1(d2(f2))。
1 2 3 4 @d1 @d2 def f () : print('f' )
相当于
1 2 3 4 def f () : print('f' ) f = d1(d2(f))
装饰器的参数化 当在源代码中解析装饰器时,Python 将被装饰的函数作为第一个参数传入装饰器。所以我们要如何让装饰器接受其他的参数呢?答案是首先创建一个接受额外参数的装饰器工厂,然后再用它生成装饰器。很乱吧?我们通过一个例子来理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 registry = [] def register (func) : print("running register(%s)" % func) registry.append(func) return func @register def f1 () : print("funning f1()" ) print("running main()" ) print("registry -> " , registry) f1()
为了让启用和禁用函数注册更加容易,我们让装饰器接受一个额外的参数 active,如果为 False,则跳过被注册函数。下面的代码实现了这个功能。从概念上讲,新的 register 函数不是一个装饰器,而是一个装饰器工厂函数,它根据参数,返回相应的装饰器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 registry = set() def register (active=True) : def decorate (func) : print("running register(active=%s)->decorate(%s)" % (active, func)) if active: registry.add(func) else : registry.discard(func) return func return decorate @register(active=False) def f1 () : print("running f1()" ) @register() def f2 () : print("running f2()" )
这里的重点在于 register() 返回装饰器 decorate,被返回的装饰器再作用于函数。
我们在中断导入这个模块可以看到:
1 2 3 4 5 >>> import registration_param running register(active=False)->decorate(<function f1 at 0x1027fe0d0>) running register(active=True)->decorate(<function f2 at 0x1027fe268>) >>> registration_param.registry {<function registration_param.f2>}
现在,仅仅 f2 被注册了;f1 没有被注册,因为 active=False 被传入了装饰器工厂。如果不使用 @ 语法糖,我们按照普通的函数调用来使用 register,那么装饰 f 的方式应该是 register()(f),或者 register(active=False)(f)。
我们现在讨论的参数化的装饰器还是要比大多数简单的。如果我们要让装饰器接受额外的参数,并且要用新的函数还替换被装饰函数,那么我们的装饰器工厂就又会多一层嵌套。
现在,我们回顾下 clock 装饰器,希望让它可以接受新的参数来控制输出格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import timeDEFAULT_FMT = '[{elapsed:0.8f}s] {name}({args}) -> {result}' def clock (fmt = DEFAULT_FMT) : def decorate (func) : def clocked (*_args) : t0 = time.time() _result = func(*_args) elapsed = time.time() - t0 name = func.__name__ args = ', ' .join(repr(arg) for arg in _args) result = repr(_result) print(fmt.format(**locals())) return _result return clocked return decorate if __name__ == "__main__" : @clock() def snooze (seconds) : time.sleep(seconds) for i in range(3 ): snooze(.123 )
运行代码,我们可以得到:
1 2 3 [0.12418222s] snooze(0.123) -> None [0.12602901s] snooze(0.123) -> None [0.12367606s] snooze(0.123) -> None
我们传入参数:
1 2 3 4 5 6 7 8 9 import timefrom clockdeco_param import clock@clock("{name}({args}) dt={elapsed:0.3f}s") def snooze (seconds) : time.sleep(seconds) for i in range(3 ): snooze(.123 )
运行可以得到:
1 2 3 snooze(0.123) dt=0.128s snooze(0.123) dt=0.124s snooze(0.123) dt=0.125s
总结 我们从没有内嵌函数的 @register 装饰器开始,到带参数的有两层嵌套函数的 @clock(),讨论了装饰器的使用方式和工作原理,也讨论了标准库中的实用的装饰器 wraps,lru_cache,singledispatch。
为了理解装饰器的工作方式,理解 import time 和 run time 的区别,我们研究了变量作用域,闭包以及 global 和 nonlocal 关键字。